BYO Data Flows
BYO data flows allow users to incorporate custom runtimes that define every aspect of a data flow, providing the flexibility of tailored data processing with all of the operational benefits of the Nexla platform. This enables highly specialized data processing to suit specific needs.
1. BYO Flows
In BYO data flows, existing or newly created codebases can be used to specify exactly how data will be ingested, handled, and moved within the data flow, as well as define how and where the data processing code will run. Code features can also include operational enhancements, such as sending notifications to custom locations and publishing additional flow information to flow insights.
The flexibility of BYO flows facilitates a wide range of advanced data manipulation & analysis possibilities to fit even the most specialized use cases, all orchestrated within Nexla.
Currently, BYO flows are only available for use when ingesting data from and sending data to file systems.
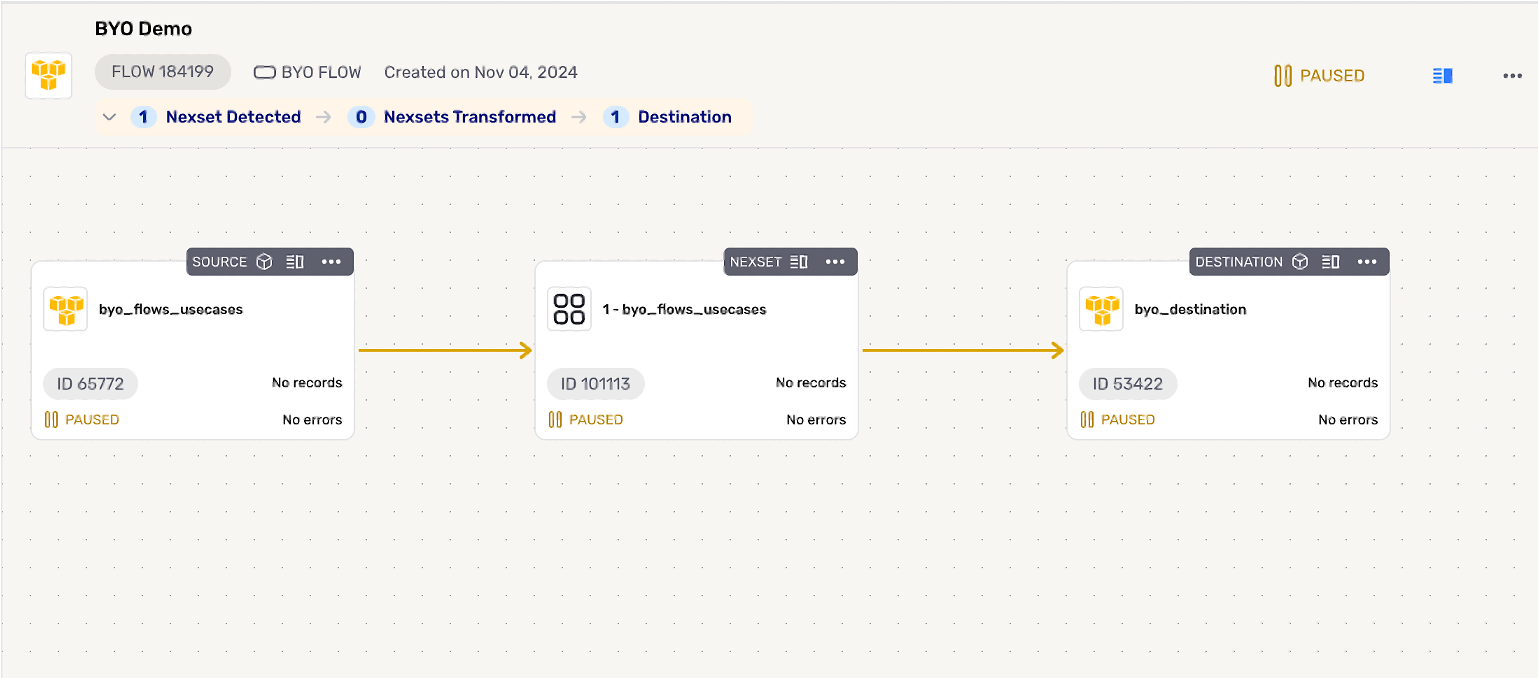
BYO Data Flow
2. Create a New BYO Data Flow
-
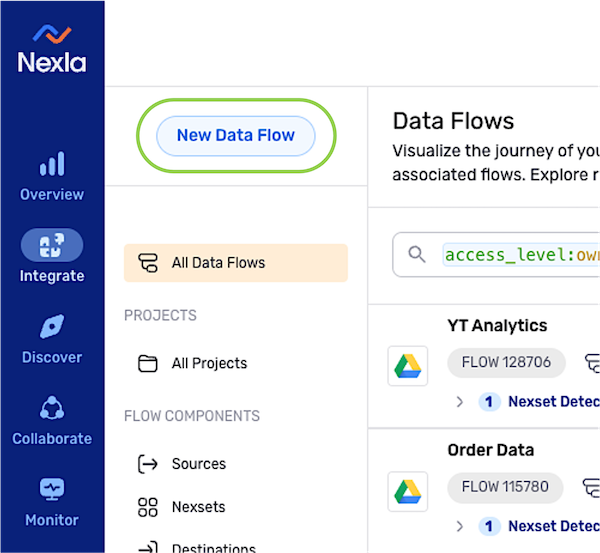
After logging into Nexla, navigate to the Integrate section by selecting
 from the platform menu on the left side of the screen.
from the platform menu on the left side of the screen. -
Click
 at the top of the Integrate toolbar on the left.
at the top of the Integrate toolbar on the left.
-
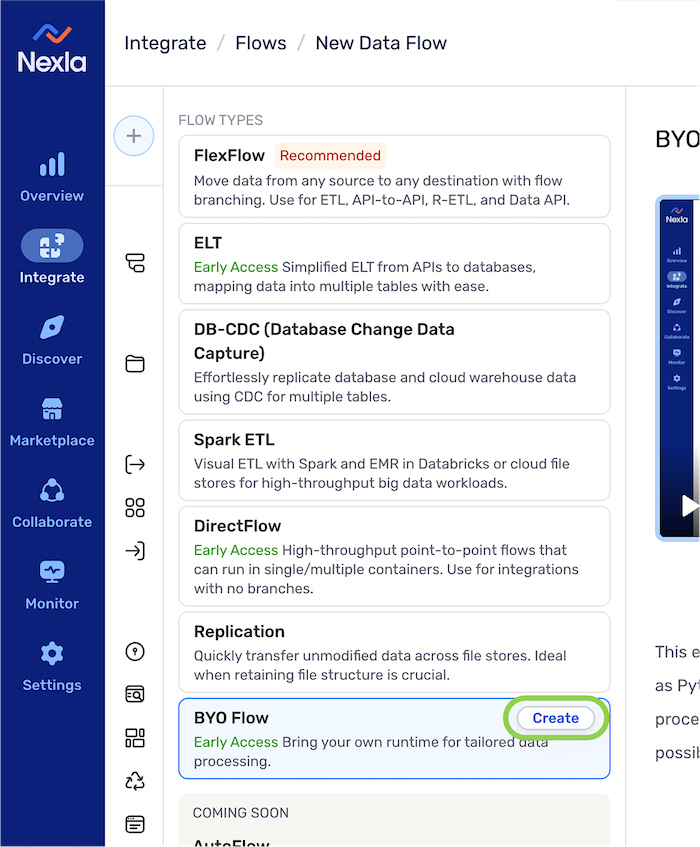
Select BYO Flow from the list of flow types, and click
 to proceed to data source creation.Learning About Flow Types
to proceed to data source creation.Learning About Flow TypesIn the Select Flow Type screen, click on a data flow type to view more information about it in the panel on the right, including a brief introductory video.
Data flows of each type can also be created by clicking the
 button at the top of this panel.
button at the top of this panel.
Authentication & Source Name
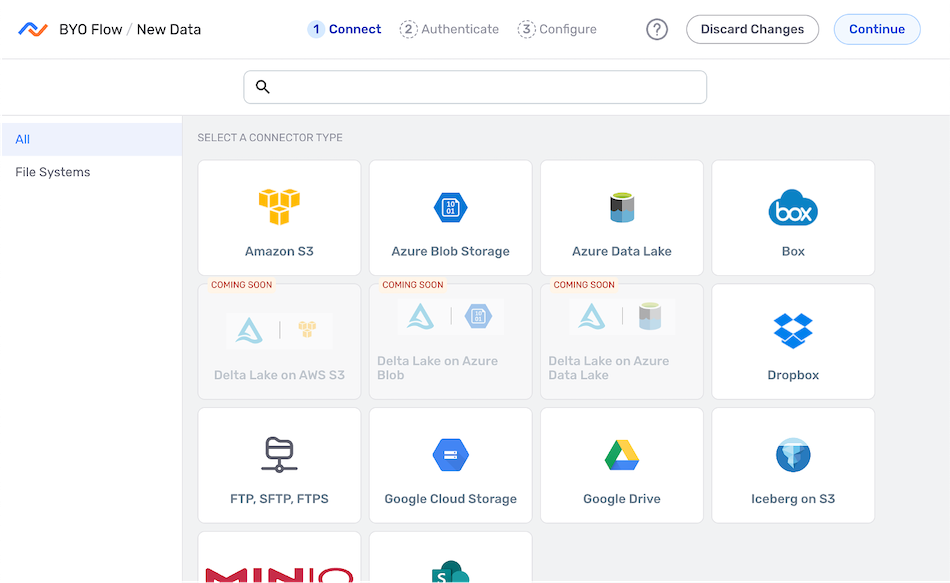
- In the Connect screen, select the connector tile matching the desired data source type from the list.
-
BYO data flows only support some of Nexla's available data source types, and only supported connectors are shown in the Connect screen.
-
To create a data flow with a data source type not available in this screen, use the FlexFlow flow type or one of the other flow types listed on the Nexla Data Flow Types page.
-
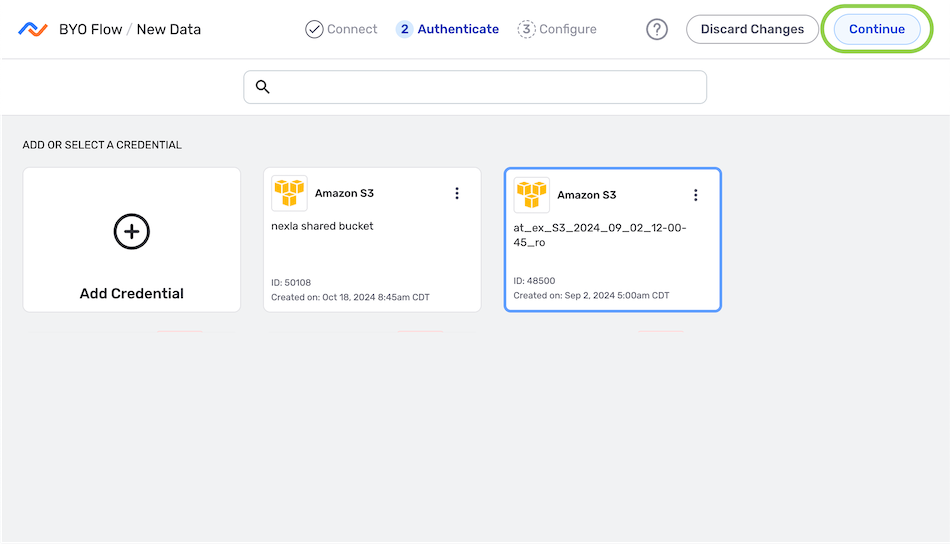
- In the Authenticate screen, select or create the credential that will be used to connect to the data source, and click
 . Detailed information about credential creation for specific sources can be found on the Connectors page.
. Detailed information about credential creation for specific sources can be found on the Connectors page.
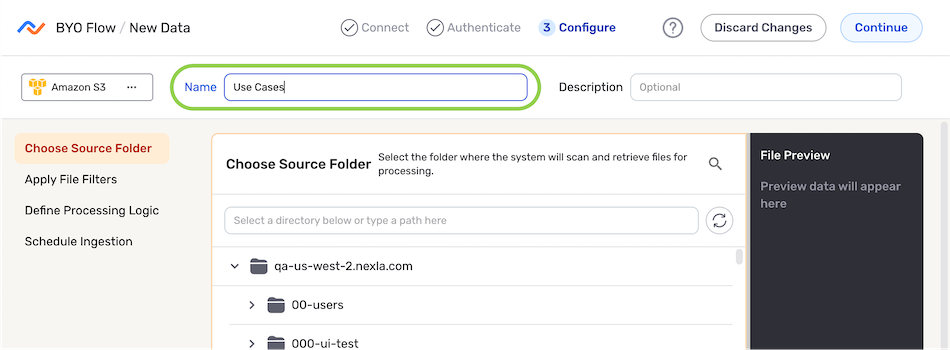
- Enter a name for the data source in the Name field.
-
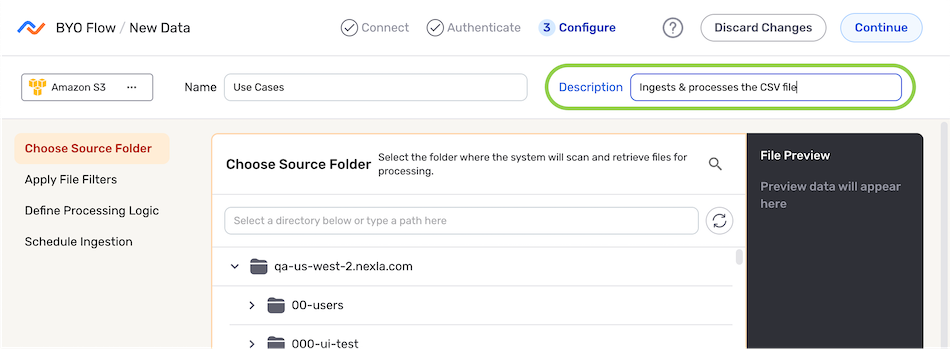
Optional: Enter a description of the data source in the Description field.
Resource DescriptionsResource descriptions should provide information about the resource purpose, data freshness, etc. that can help the owner and other users efficiently understand and utilize the resource.
-
Select the data source directory, and configure any additional source settings—such as the ingestion frequency, applied file filters, etc.—according to the source type.
Configuring a Data SourceFor information about configuring each data source type, see the following pages in the Connectors section:
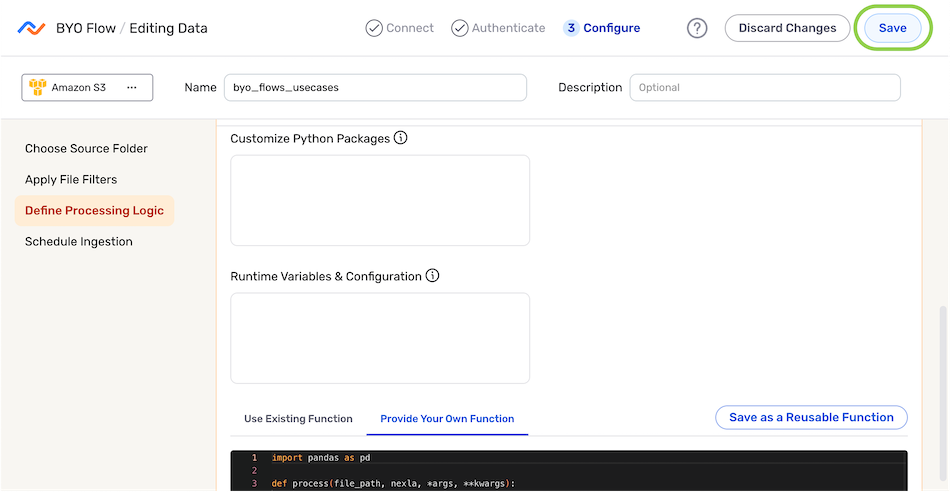
Define the Processing Logic
Under the Define Processing Logic settings section, users can enter or select the function that will be used to define this data flow, as well as incorporate any desired packages, runtime variables, and/or runtime configurations.
-
Optional: Nexla includes common Python packages used for data processing; however, users can override these packages and/or incorporate additional packages for use in the processor function for this BYO flow. To customize the Python packages for this flow, enter the desired packages in the Customize Python Packages field in the format
p1=1.0.1.Custom Python Packages in BYO FlowsWhen custom Python packages are specified for a BYO flow, Nexla will install these packages in the environment where the flow processor function runs.
To add multiple packages, separate the entries with a comma—i.e.,
p1==1.0.1,p2==0.0.2.
-
To pass additional variables and/or configurations to the custom processor function for this flow, enter this information in the Runtime Variables & Configuration field.
Custom Variables & Configurations in BYO FlowsCustom variables & configurations are useful for passing any needed additional configurations and/or runtime variables to the BYO flow custom processor function.
Variables/configurations must be entered as valid JSON objects with the following optional special keys:
custom_code– an object containing custom code configurationsargs– a list of arguments to be passed to the custom code functionkwargs– a dictionary of keyword arguments to be passed to the custom code function
job_config– an object containing job-specific configurations to override platform defaults (contact Nexla Support for recommendations based on the use case)
-
Select or provide the custom processor function that will be used for this flow.
-
To select an existing function:
- Under the Use Existing Function tab, click Find an Existing Custom Processor.
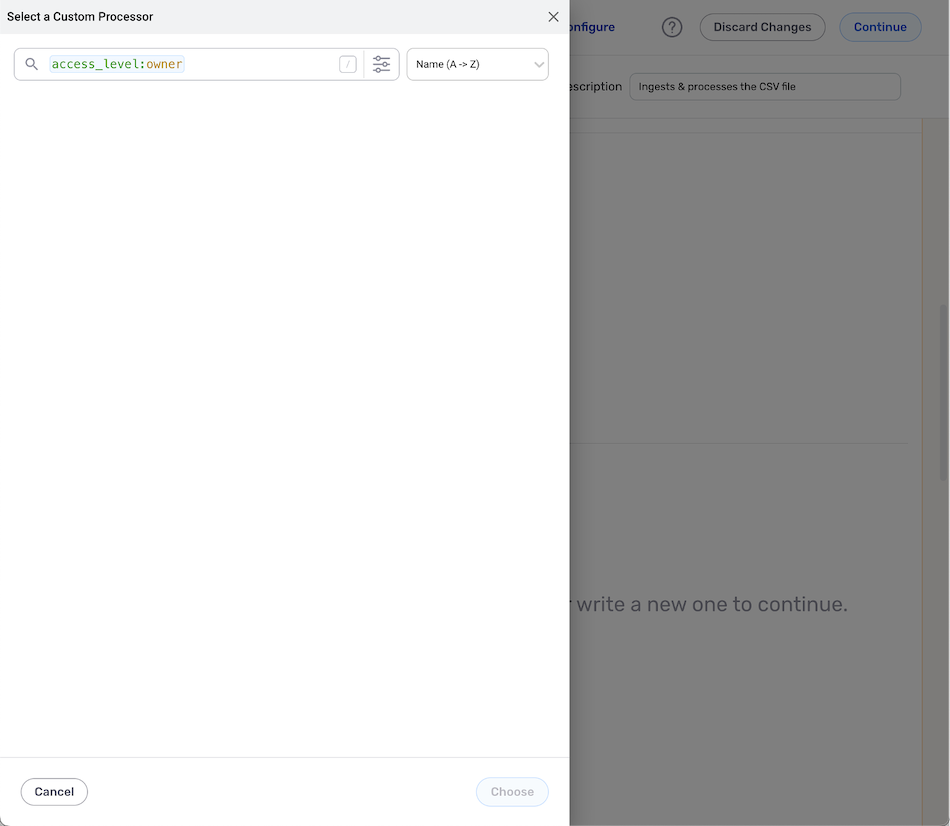
- Locate and select the custom processor in the Select a Custom Processor drawer, and then click Choose.
-
To define a new function:
- Select the Provide Your Own Function tab, and enter the processor function within the text field.
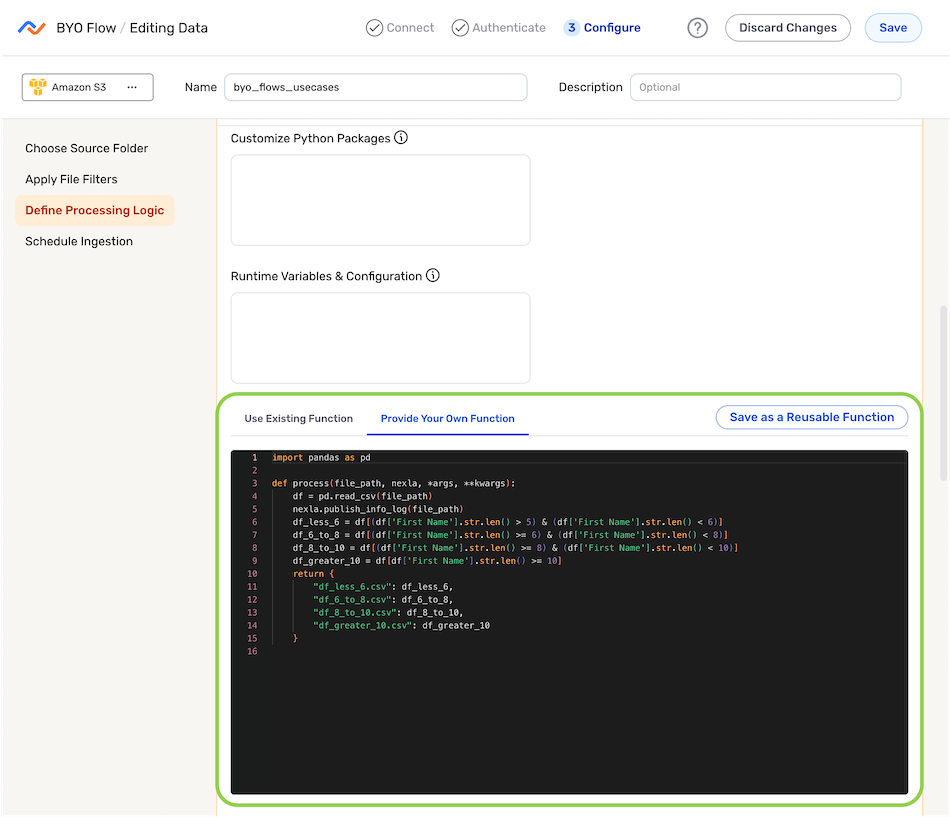
- Optional: To save this function as a reusable function for use in other BYO data flows, click Save as a Reusable Function.
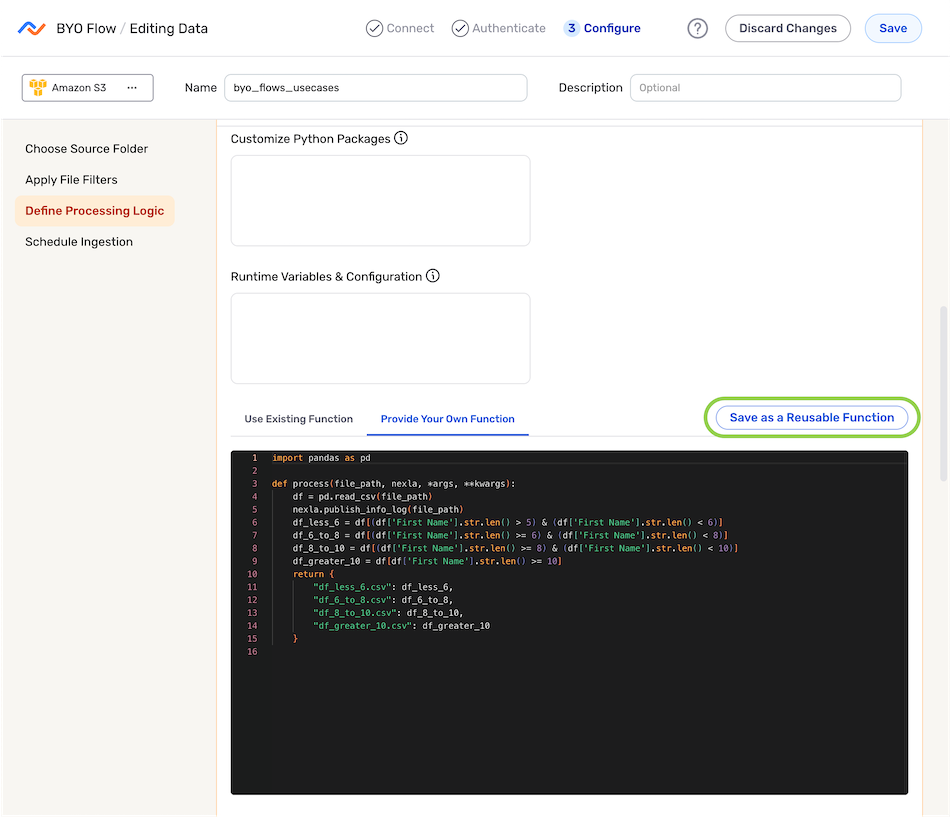
-
Test the Function Output
- Under Test Output, enter the path to a file that will be used to test the processor function in the File Path field.
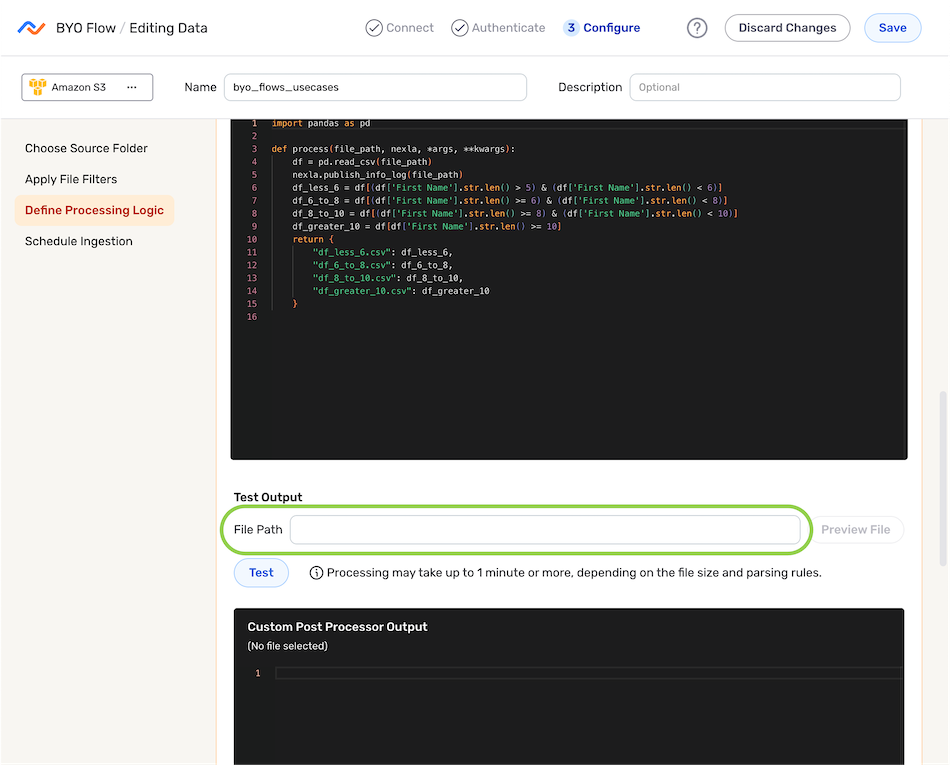
- Click Test to generate a preview of the custom processor function output in the Custom Post Processor Output field.
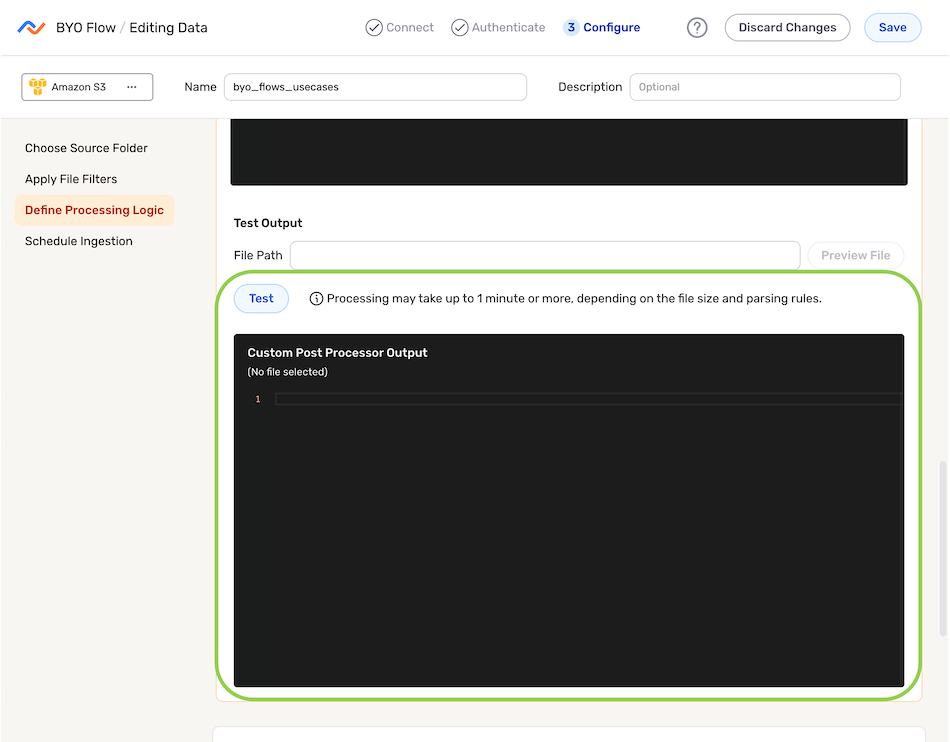
Save & Activate the Data Flow
- After defining the custom processor function and configuring all necessary additional settings, click
 in the upper right corner of the screen to save and create the data flow.
Important: Data Movement
in the upper right corner of the screen to save and create the data flow.
Important: Data MovementData will not begin to be processed in the data flow until it is activated, as shown in the following step.
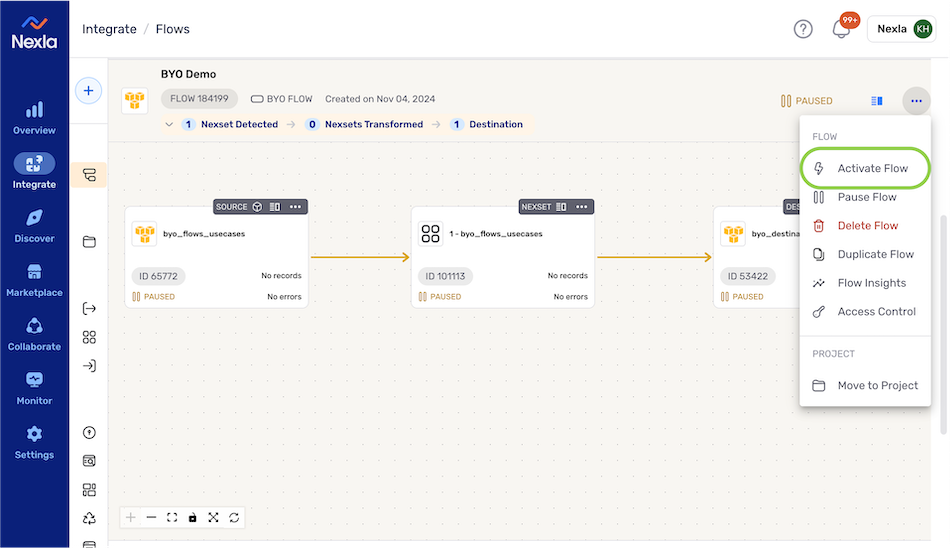
- Once the data flow is created, it must be activated to begin the processing and movement of data. To activate the flow, click
 on the data flow listing, and select
on the data flow listing, and select  from the dropdown menu.
from the dropdown menu.