Common Setup for Databases & Data Warehouses
This article provides general information about working with databases and data warehouses in Nexla.
- Detailed instructions for creating a data source or destination using any of Nexla's database/data warehouse connectors are located in Data Sources: Connecting to Databases/Data Warehouses & Data Destinations: Sending Data to Databases/Data Warehouses.
1. Databases/Data Warehouses & Nexla
Databases provide an efficient way to store, manage, and access large volumes of both structured and unstructured data. Data stored in databases is used in a wide variety of operational and transactional workflows, including retail order and inventory tracking, business decision-making, financial transaction tracking, and many others.
Data warehouses are also used to store and access large volumes of structured or unstructured data, but typically, this data is aggregated from multiple sources and includes both current and historical data. Data stored in data warehouses is used to support workflows such as in-depth data analytics, data mining, artificial intelligence, and machine learning.
Examples of databases and data warehouses include Google BigQuery, Snowflake, RedShift, MySQL, and Oracle Autonomous.
Nexla can connect to and ingest data from any database or data warehouse, allowing users to quickly and easily build data flows that ingest data from these sources, apply any needed transformations, and send the data to any destination. Data flows originating from databases and data warehouses can be constructed to suit any use case, and Nexla's comprehensive governance and troubleshooting tools allow users to monitor every aspect of the flow status, data lineage, and more.
2. Data Sources: Connecting to Databases/Data Warehouses
With Nexla's connectors, users can quickly and easily add any database or data warehouse as a data source to begin ingesting, transforming, and moving data in any format.
Each of Nexla's data flow types includes destination configuration options that are specific to the flow type. Click the link corresponding to your flow type in the list below to learn how to configure the destination and complete the destination setup process.
▷ FlexFlow Data Flows
▷ DB-CDC Data Flows
▷ Spark ETL Data Flows
▷ Replication Data Flows
▷ DirectFlow Data Flows
FlexFlow:
FlexFlow is a flexible all-in-one data flow type that can be used to create both streaming and real-time data flows that can be used to transform data and/or move data from any source to any destination. This flow type uses the Kafka engine to facilitate seamless high-throughput movement of data from any source to any destination. FlexFlow is the recommended flow type for most workflows.
DB-CDC:
DB-CDC data flows use change data capture to replicate tables across databases and/or cloud warehouses. This flow type is streamlined for use in data migration and maintenance workflows, allowing users to quickly create data flows that replicate data across storage locations.
Spark ETL:
Spark ETL data flows are designed for rapidly modifying large volumes of data stored in cloud databases or Databricks and moving the transformed data into another cloud storage or Databricks location. This flow type uses the Apache Spark engine and is ideal for large-scale data processing wherein minimizing latency in data movement is a critical need.
Replication:
Replication data flows are designed for use in workflows that require high-speed movement of unmodified files between storage systems. This flow type is ideal for use when both retaining file structure and transferring data as quickly as possible are critical.
DirectFlow:
DirectFlow data flows are designed for high-throughput point-to-point data processing wherein minimizing data processing latency is a critical need. This flow type is ideal for use in batch processing with non-streaming data sources & destinations.
ELT:
ELT data flows are streamlined for seamless movement of unmodified data from APIs into databases and data warehouses. With minimal configuration required, these flows can be set up rapidly and effortlessly to support ELT workflows.
FlexFlow Data Flows
-
After logging into Nexla, navigate to the Integrate section by selecting
 from the platform menu on the left side of the screen.
from the platform menu on the left side of the screen. -
Click
 at the top of the toolbar on the left.
at the top of the toolbar on the left.
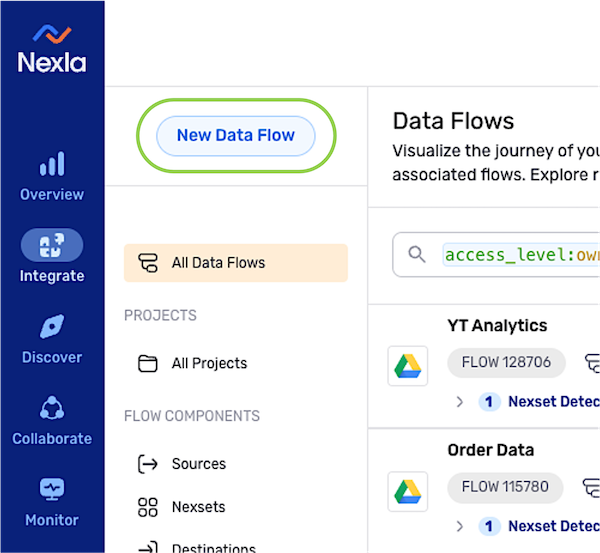
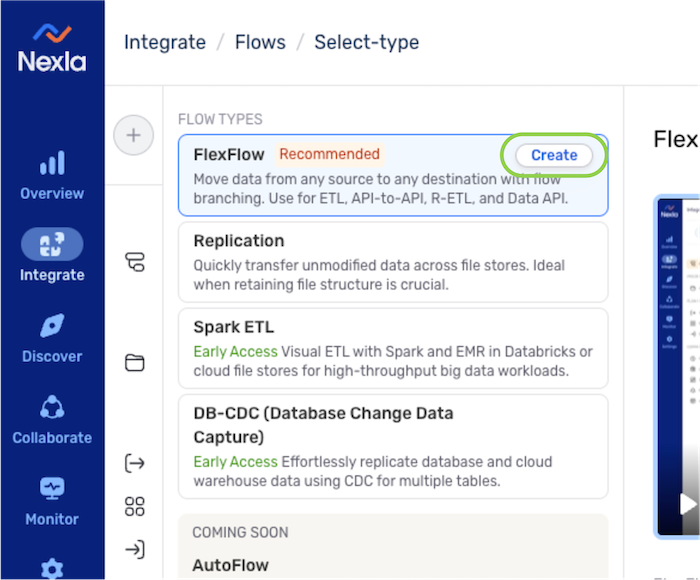
- Select FlexFlow from the list of flow types, and click
 to proceed to data source creation.
to proceed to data source creation.
- Select the connector tile that matches the database/data warehouse from which data will be ingested in this flow. Then, click
 in the top right corner of the screen. Once a connector is selected, the platform will automatically advance to the next setup step.
in the top right corner of the screen. Once a connector is selected, the platform will automatically advance to the next setup step.
To view all of Nexla's currently available database/data warehouse connectors, select Databases from the Categories toolbar on the left side of the screen.

-
In the Authenticate screen, follow the instructions below to create or select the credential that will be used to connect to the data source.
To create a new credential:
- Select the Add Credential tile.
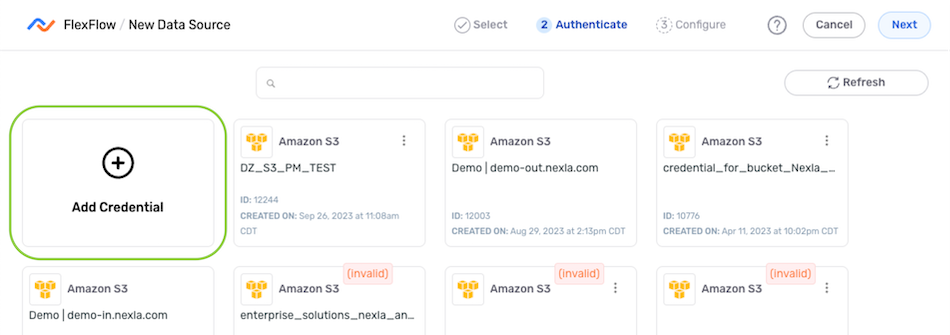
- Enter and/or select the required information in the Add New Credential pop-up.
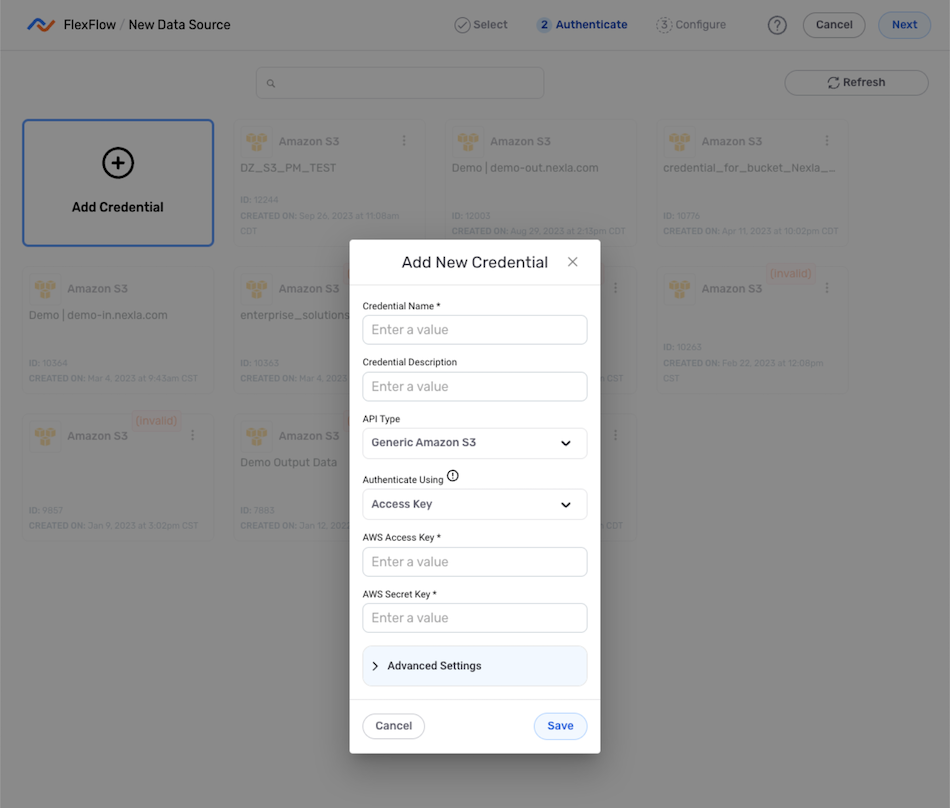
- Once all of the required information has been entered, click
 at the bottom of the pop-up to save the new credential, and proceed to Configure the Data Source.
at the bottom of the pop-up to save the new credential, and proceed to Configure the Data Source.
To use a previously added or shared credential:
- Select the credential from the list.
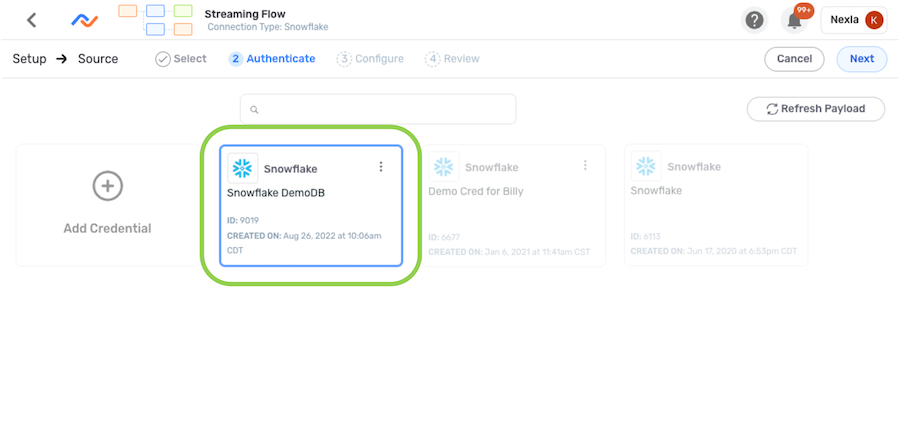
- Click in the upper right corner of the screen, and proceed to Configure the Data Source.
Configure the Data Source
In Nexla, database & data warehouse data sources can be configured using either Table Mode or Query Mode.
This section provides instructions for configuring the source using Table Mode, which allows users to specify which data should be ingested from the database source through a simple selection method. This mode is equivalent to running a simple, optimized SELECT operation on any database/data warehouse table.
Query Mode allows users to enter a query to selectively fetch specific data from the source. This mode provides a free-form query editor that can be used to write queries using the syntax and convention supported by the underlying database. Queries of any complexity level can be executed, as long as they adhere to the supported syntax.
To learn how to configure database & data warehouse sources using Query Mode, see the Query Mode section in Database Sources - Table Mode & Query Mode.
-
In the Configure screen, enter a name for the data source in the Source Name or Name field.
-
Optional: Enter a brief description of the data source in the Description field (if present).
Resource DescriptionsResource descriptions should provide information about the resource purpose, data freshness, etc. that can help the owner and other users efficiently understand and utilize the resource.
-
The subsections below provide information about additional settings available for database & data warehouse sources in FlexFlow data flows. Follow the listed instructions to configure each setting for this data source, and then proceed to Save & Activate the Data Source.
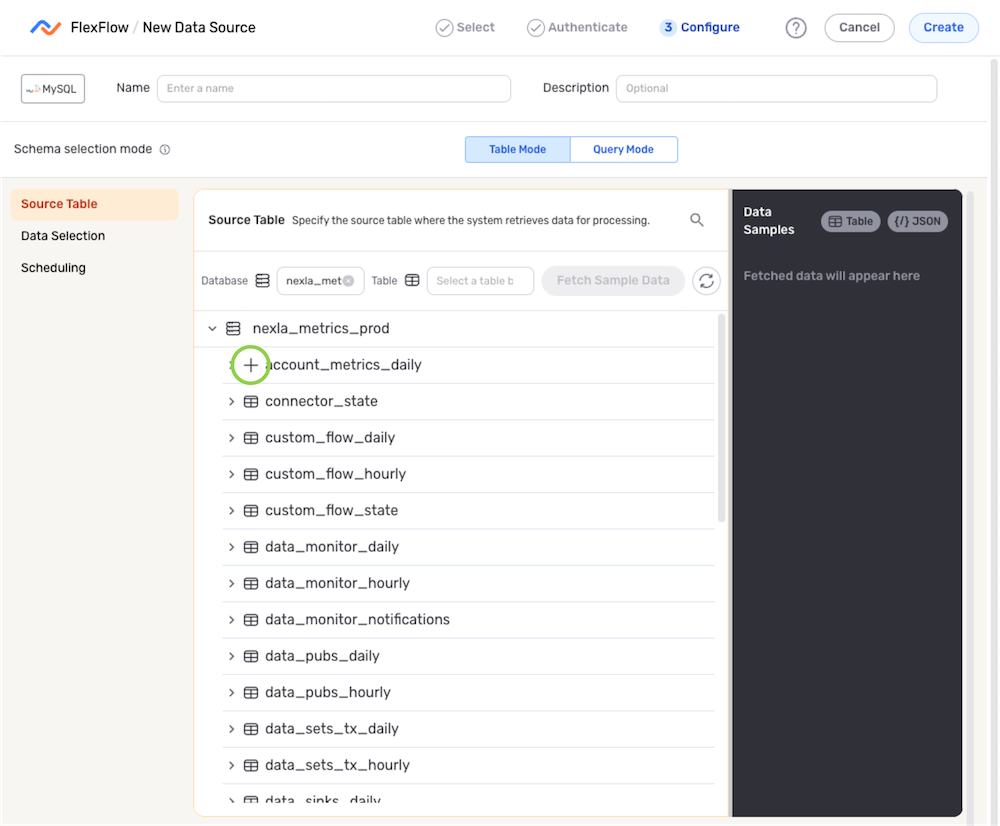
Source Table
In Nexla, database & data warehouse sources can be configured to ingest all data in a location accessible to the selected credential, only data in tables within a specific directory, or only data from a single table.
-
Under the Source Table section, navigate to the directory location from which Nexla should read data; then, hover over the listing, and click the
 icon to select this location.
icon to select this location.- To view/select a nested location, click the
 icon next to a listed folder to expand it.
icon next to a listed folder to expand it.
- To view/select a nested location, click the
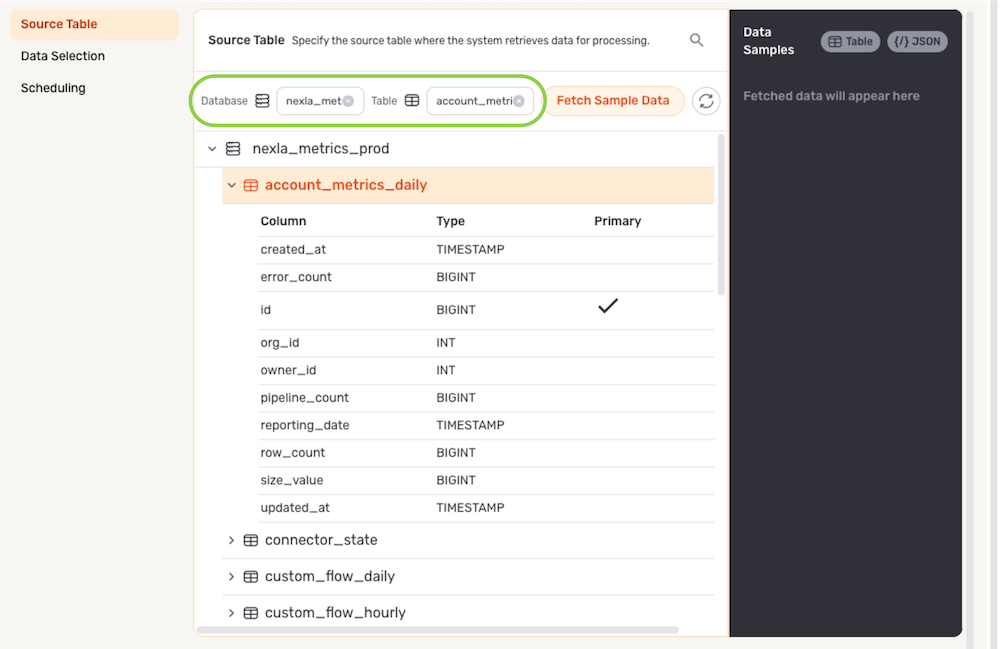
- The selected directory location is displayed at the top of the Source Table section.
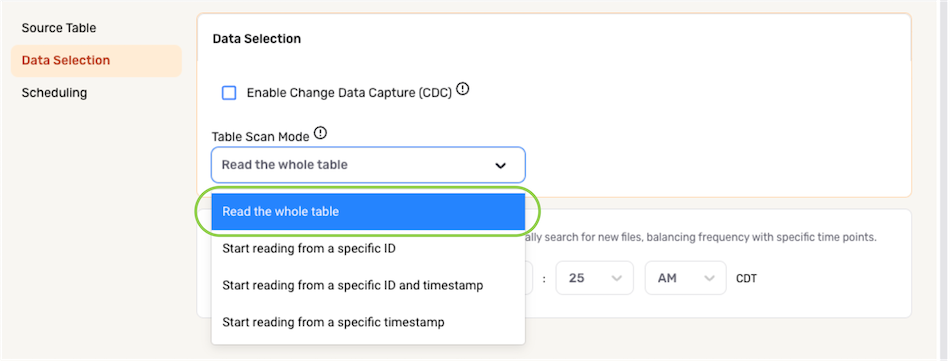
Data Selection (Full/Partial Data Loading)
When setting up a database/data warehouse source in a data flow, Nexla provides configuration options for specifying which data should be ingested from the source location, allowing users to customize data ingestion to suit various use cases. Partial data loading from the selected location can be configured using record IDs and/or timestamps using the table scan modes available under the Data Selection category.
▷ Full data loading from the selected location:
-
To configure Nexla to ingest all data from the selected database location, select Read the whole table from the Table Scan Mode menu.
▷ Partial data loading according to a record ID:
- To configure Nexla to ingest data from the selected location by beginning at a specified record ID, select Start reading from a specific ID from the Table Scan Mode menu.
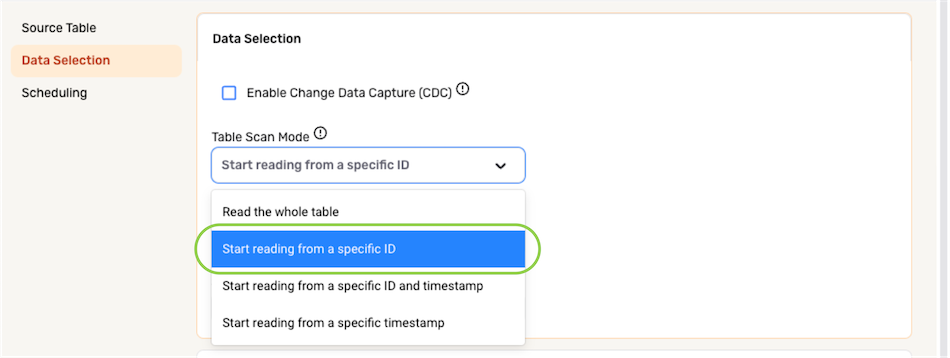
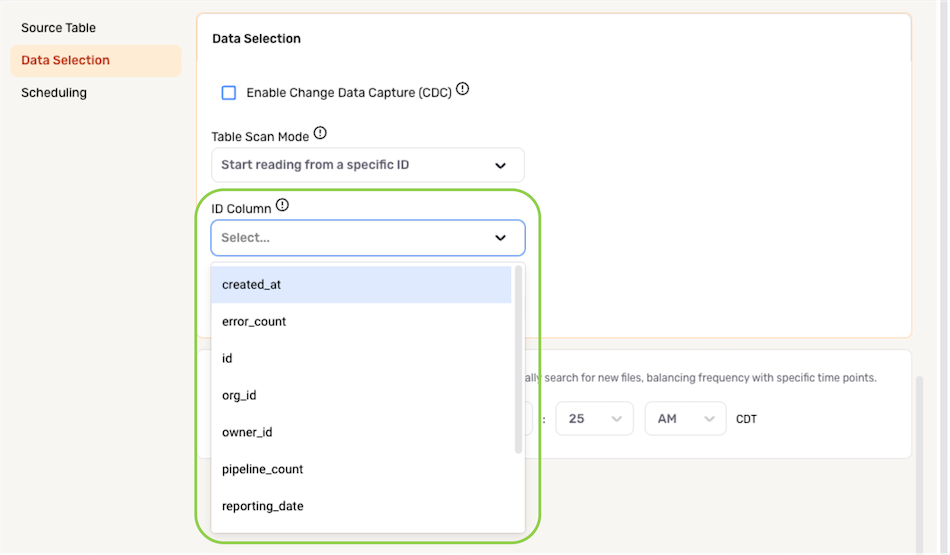
- Select the column containing the ID that will be used to execute partial data loading from the ID Column pulldown menu.
The ID Column must be a numeric column.
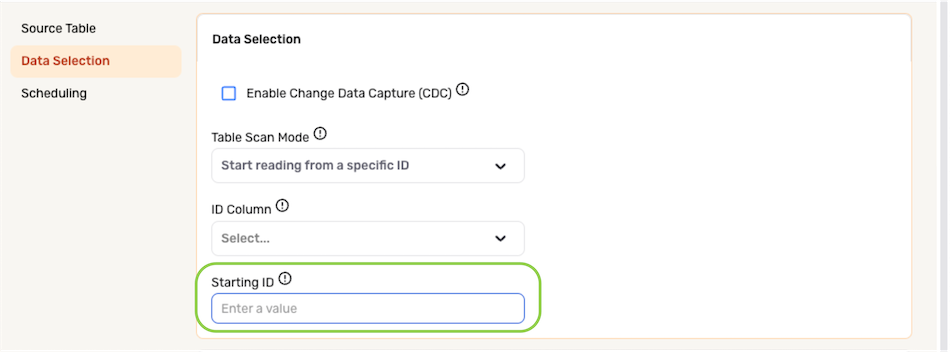
- Enter the ID value from which Nexla should start ingesting data in the Starting ID field.
The Starting ID must be an value located in the ID Column selected in the previous step.
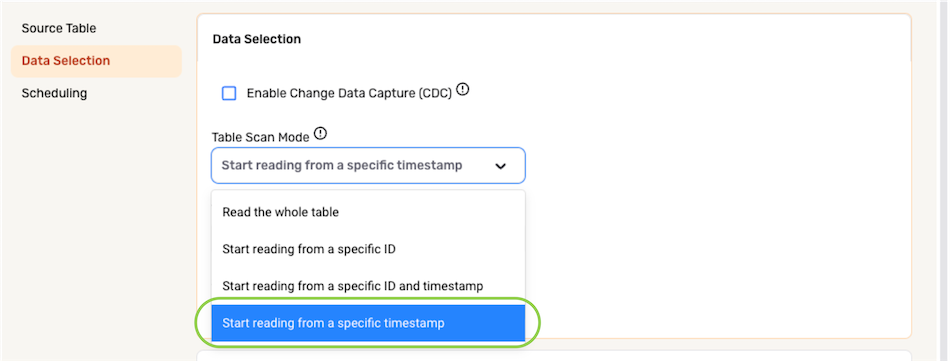
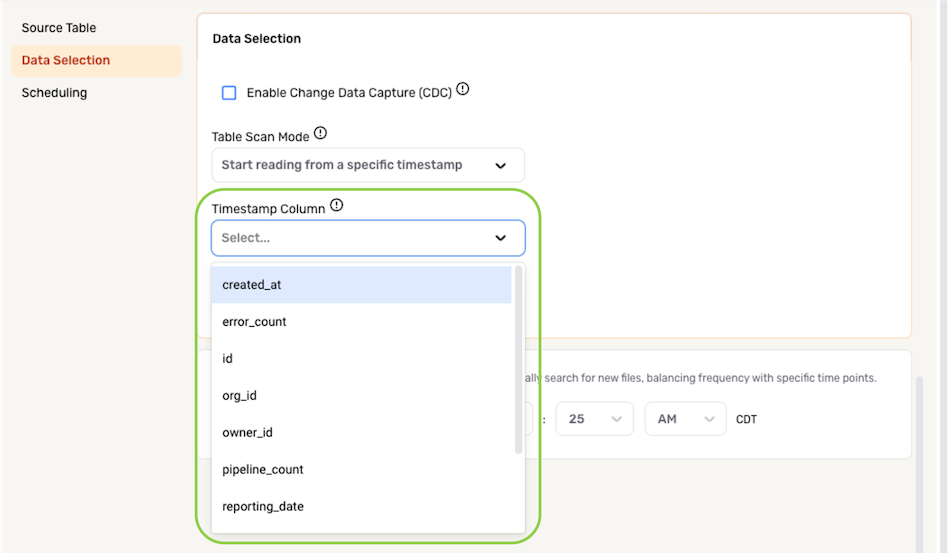
▷ Partial data loading according to a timestamp:
- To configure Nexla to ingest data from the selected location by beginning at a specified timestamp, select Start reading from a specific timestamp from the Table Scan Mode menu.
- Select the column containing the timestamp that will be used to execute partial data loading from the Timestamp Column pulldown menu.
The Timestamp Column must be a datetime column.
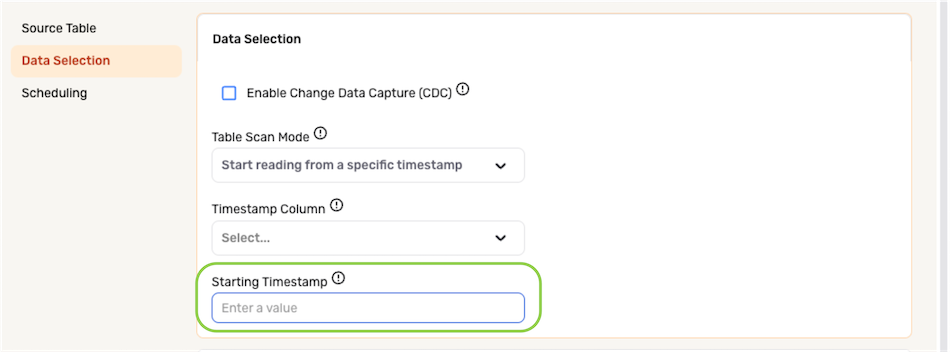
- Enter the timestamp value from which Nexla should start ingesting data in the Starting Timestamp field.
The Starting Timestamp must be a UNIX epoch (milliseconds)- or ISO-formatted date value—e.g., 2016-01-01T12:13:14. This timestamp must also be a value located in the Timestamp Column selected in the previous step.
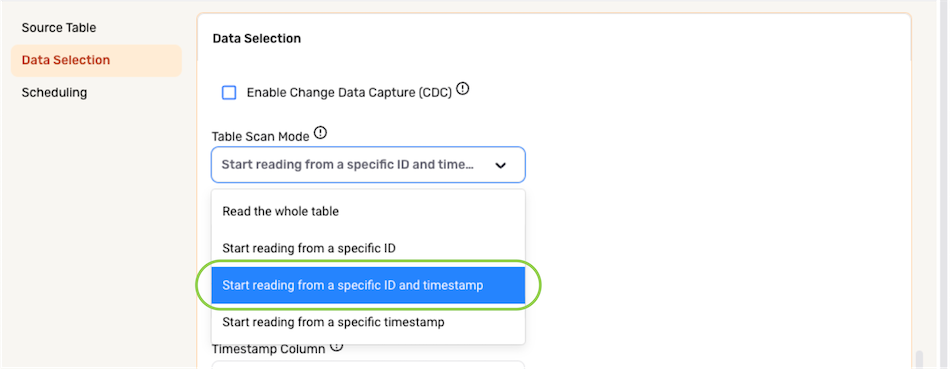
▷ Partial data loading according to both a record ID & a timestamp:
- To configure Nexla to ingest data from the selected location by beginning at a specified ID & timestamp, select Start reading from a specific ID and timestamp from the Table Scan Mode menu.
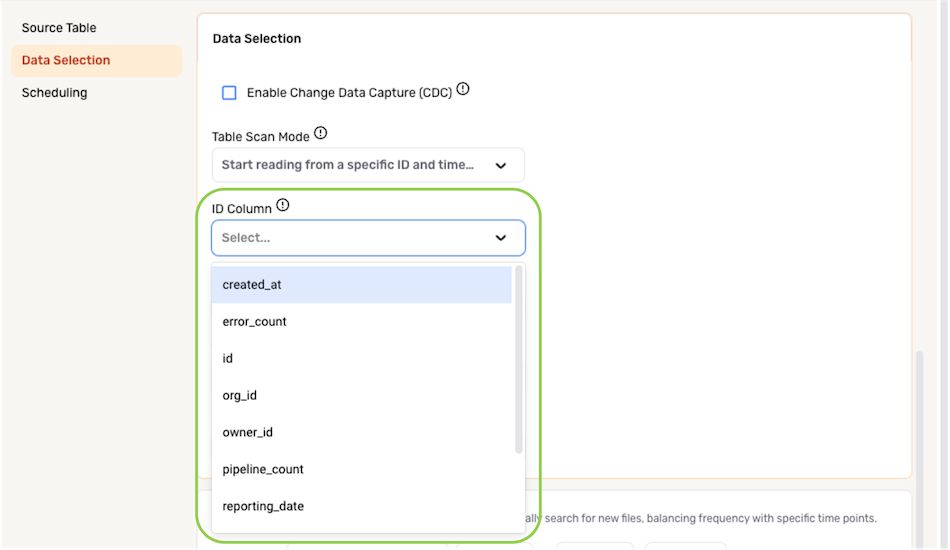
- Select the column containing the ID that will be used to execute partial data loading from the ID Column pulldown menu.
The ID Column must be a numeric column.
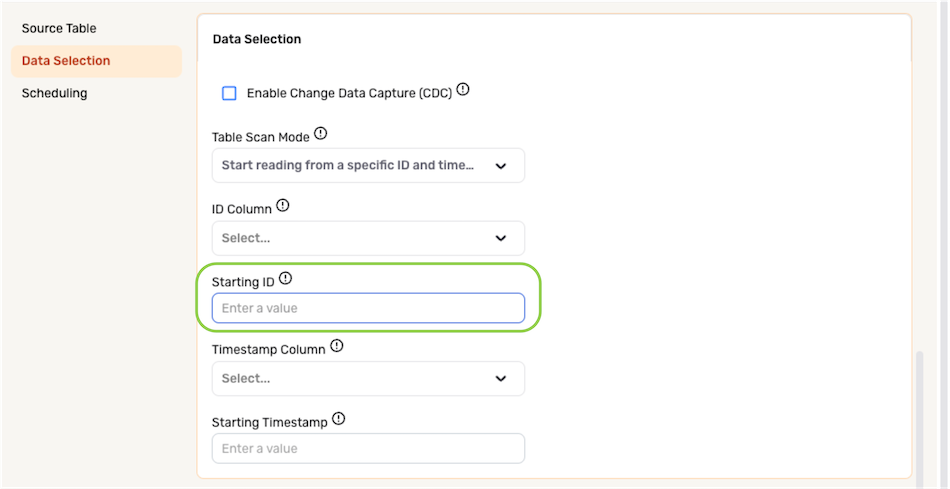
- Enter the ID value from which Nexla should start ingesting data in the Starting ID field.
The Starting ID must be an value located in the ID Column selected in the previous step.
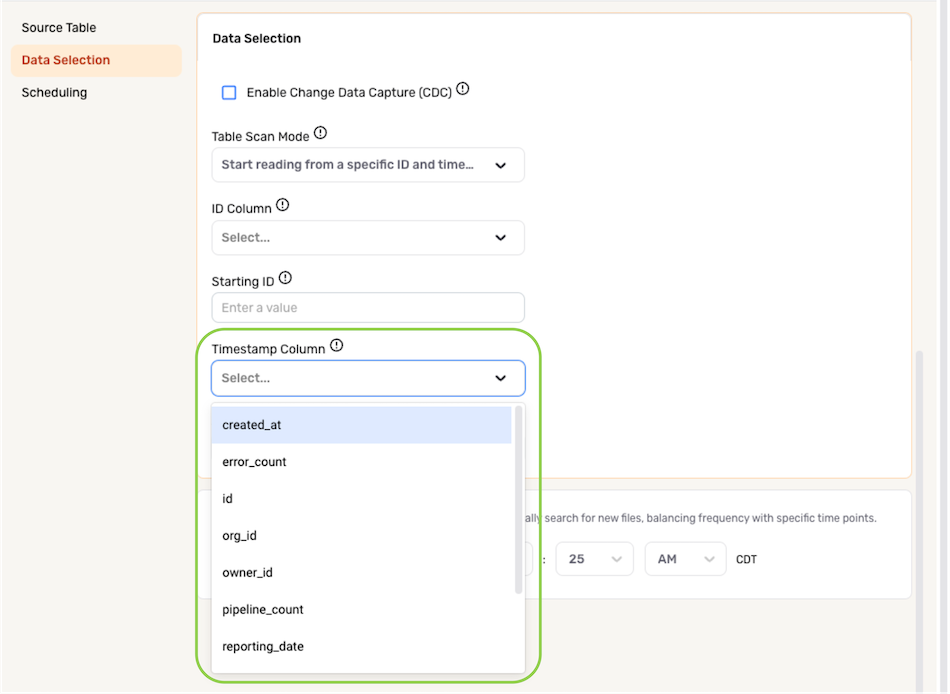
- Select the column containing the timestamp that will be used to execute partial data loading from the Timestamp Column pulldown menu.
The Timestamp Column must be a datetime column.
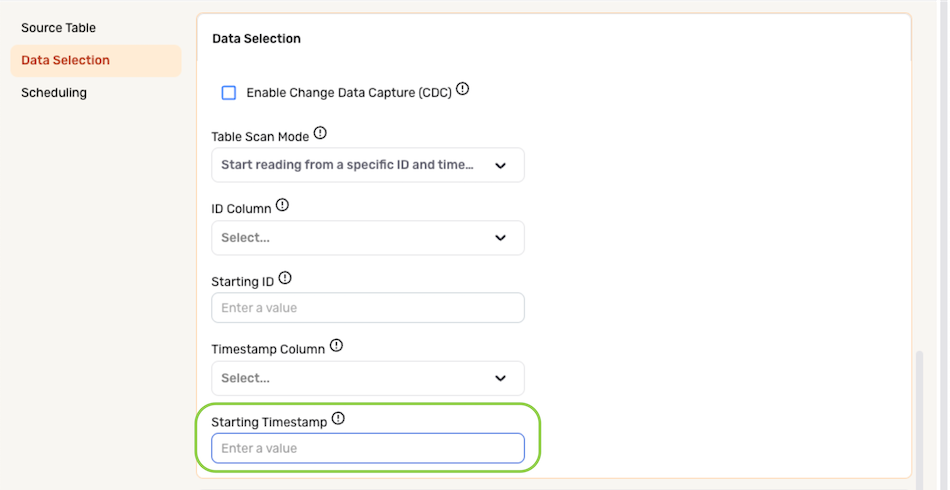
- Enter the timestamp value from which Nexla should start ingesting data in the Starting Timestamp field.
The Starting Timestamp must be a UNIX epoch (milliseconds)- or ISO-formatted date value—e.g., 2016-01-01T12:13:14. This timestamp must also be a value located in the Timestamp Column selected in the previous step.
Scheduling
Scan scheduling options can be used to define the frequency at which the selected location will be scanned for new data and/or changes in a data flow. Any new data/changes identified during a scan will then be ingested into the flow.
-
By default, when a new data flow is created, Nexla is configured to scan the source for data changes once every day. To continue with this setting, no further selections are required. Proceed to Save & Activate the Data Source.
-
To define how often Nexla should scan the data source for new data changes, select an option from the Fetch Data pulldown menu under the Scheduling section.
- When options such as Every N Days or Every N Hours, a secondary pulldown menu will be populated. Select the appropriate value of N from this menu.
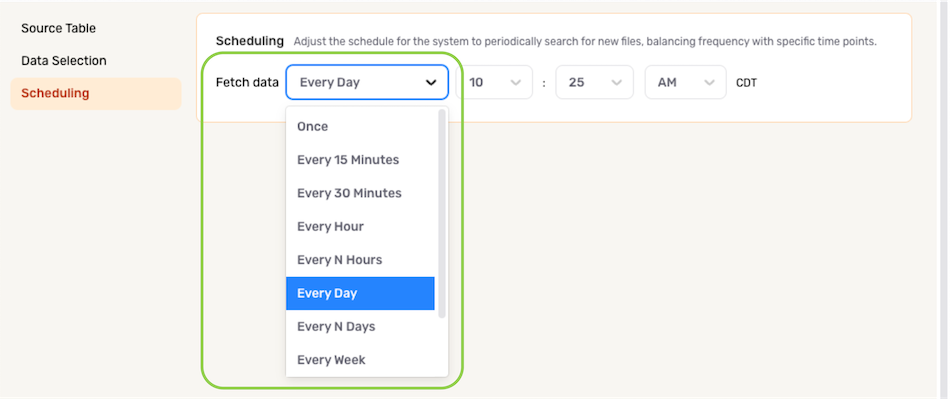
- To specify the time at which Nexla should scan the source for new data changes, use the pulldown menu(s) to the right of the Fetch Data menu. These time menus vary according to the selected scan frequency.

Save & Activate the Data Source
After all required settings and any desired additional options are configured, click ![]() in the top right corner of the screen to save & activate the data source.
in the top right corner of the screen to save & activate the data source.
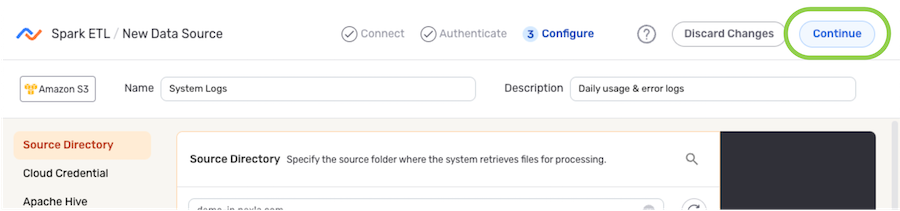
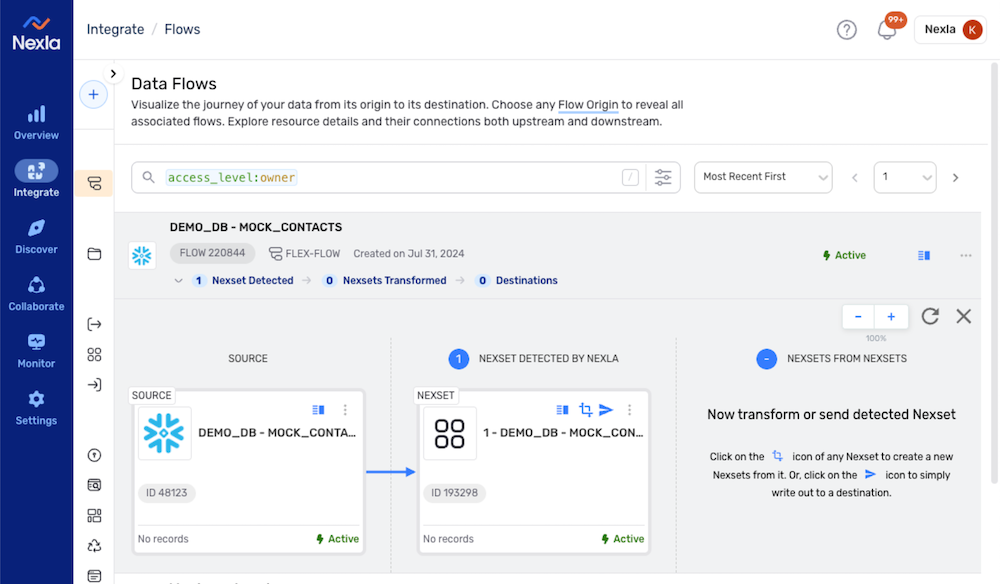
Once the data source is created, Nexla will automatically scan it for data according to the configured settings. Identified data will be organized into a Nexset, which is a logical data product that is immediately ready to be sent to a destination.
DB-CDC Data Flows
-
After logging into Nexla, navigate to the Integrate section by selecting
from the platform menu on the left side of the screen. -
Click
at the top of the Integrate toolbar on the left.
- Select DB-CDC from the list of flow types, and click to proceed to data source creation.
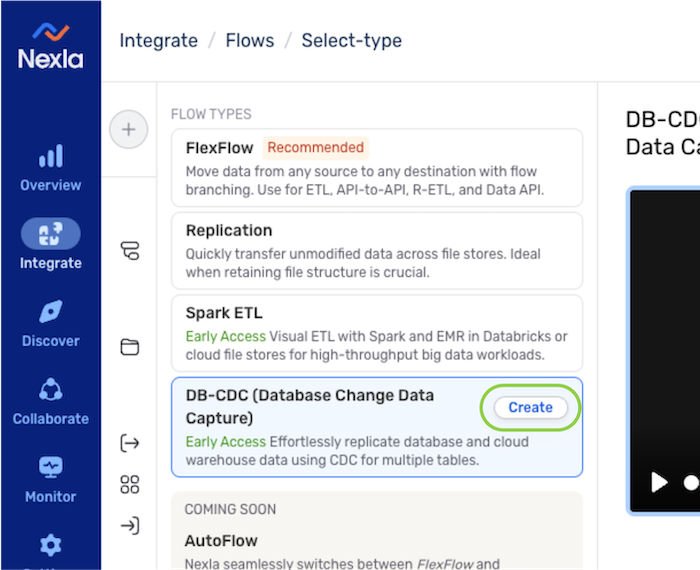
- In the Connect screen, select the connector tile matching the data source type from the list.
DB-CDC data flows are only supported for some of the connectors available in Nexla, and only supported connectors are shown on this screen.
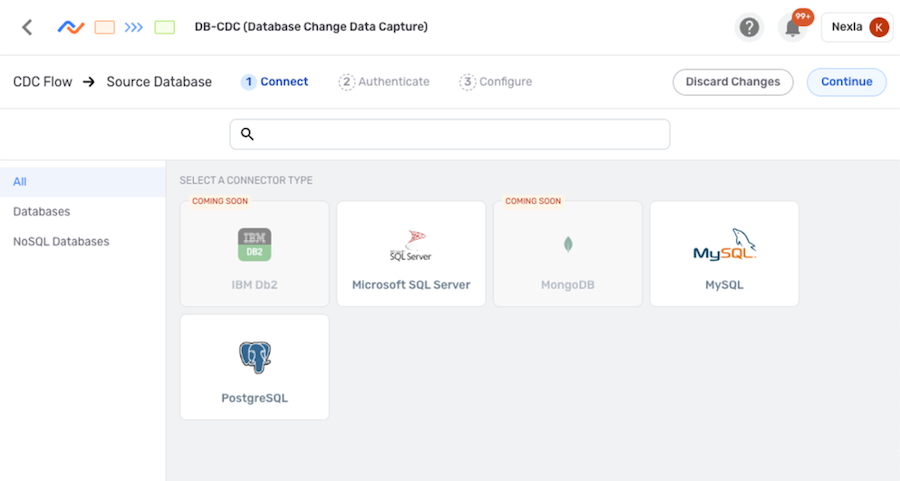
- In the Authenticate screen, follow the instructions below to create or select the credential that will be used to connect to the data source.
The credentials used to create the data source in a DB-CDC flow must have permission to read transaction logs from the source location. More information can be found in DB-CDC Data Flows.
To create a new credential:
- Select the Add Credential tile.
- Enter and/or select the required information in the Add New Credential pop-up.
- Once all of the required information has been entered, click at the bottom of the pop-up to save the new credential, and proceed to Configure the Data Source.
To use a previously added or shared credential:
- Select the credential from the list.
- Click in the upper right corner of the screen, and proceed to Configure the Data Source.
Configure the Data Source
- Enter a name for the data source in the Source Name field.
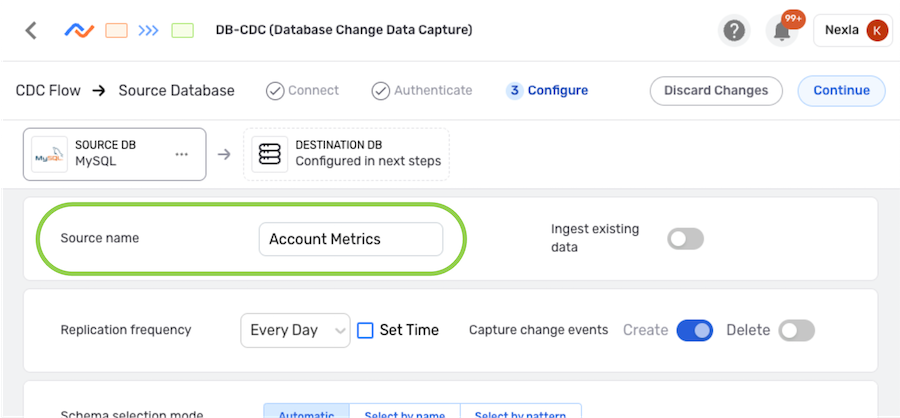
- The subsections below provide information about additional settings available for data sources in DB-CDC flows. Follow the listed instructions to configure each setting for this data source, and then proceed to Save & Activate the Data Source.
Data Selection
With DB-CDC flows in Nexla, users can define which data from the source location will be reflected into the destination. Source data in these flows can be configured to include the entire database associated with the data source credential or to include or exclude specified tables.
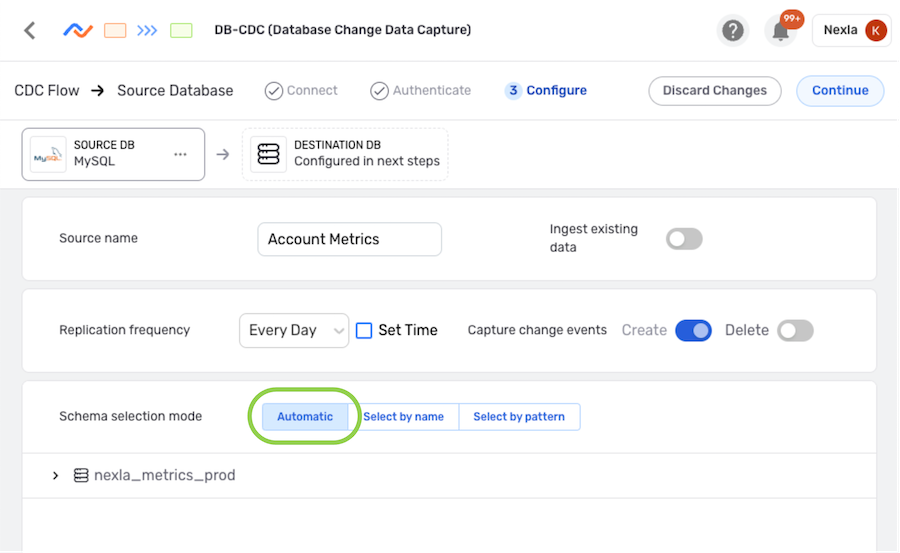
▷ Include all data in the source location:
- Select the Automatic schema selection mode. When this mode is used, all data accessible to the credential used to create the data source will be reflected into the destination.
Example: All tables in the nexla_metrics_prod database will be included
in the DB-CDC flow
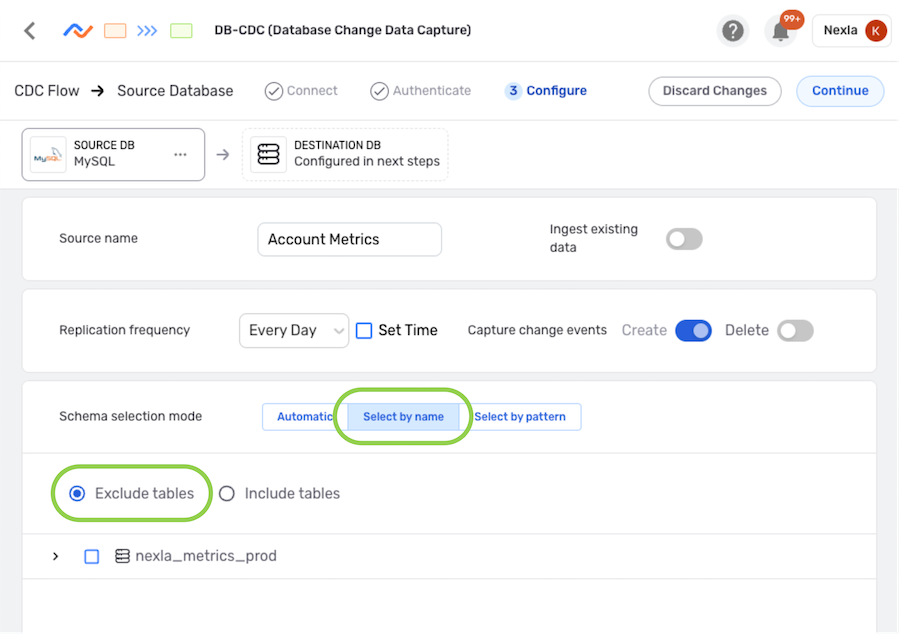
▷ Exclude some tables in the source location:
- Select the Select by name schema selection mode, and ensure that the Exclude tables option is selected.
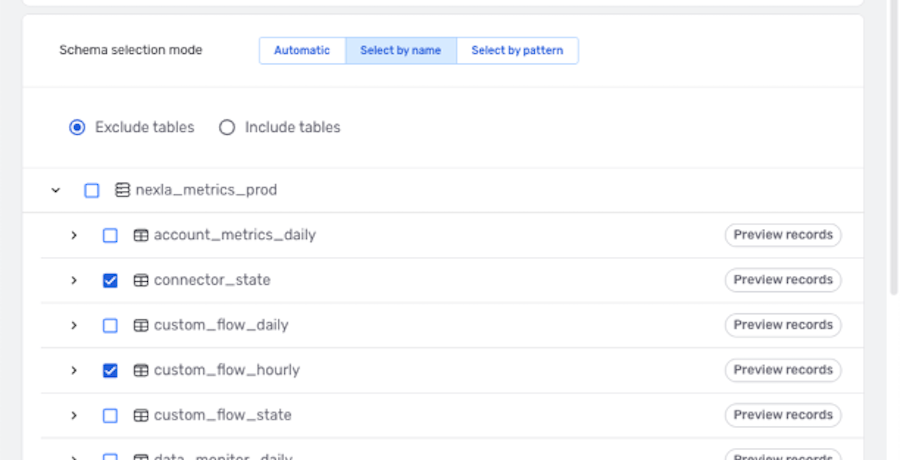
- Click the icon next to the database name to expand the list of tables, and check the box(es) next to the table(s) that should be excluded from this DB-CDC flow.
Example: Data in the connector_state and custom_flow_hourly tables will be
excluded from the DB-CDC flow
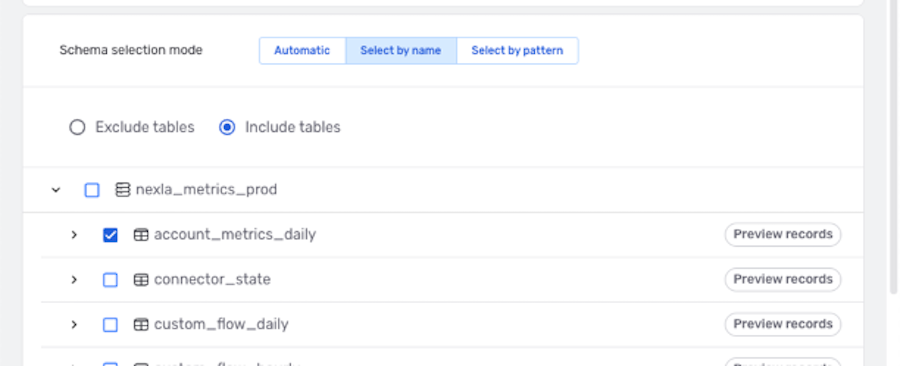
▷ Include only some tables in the source location:
- Select the Select by name schema selection mode, and select the Include tables option.
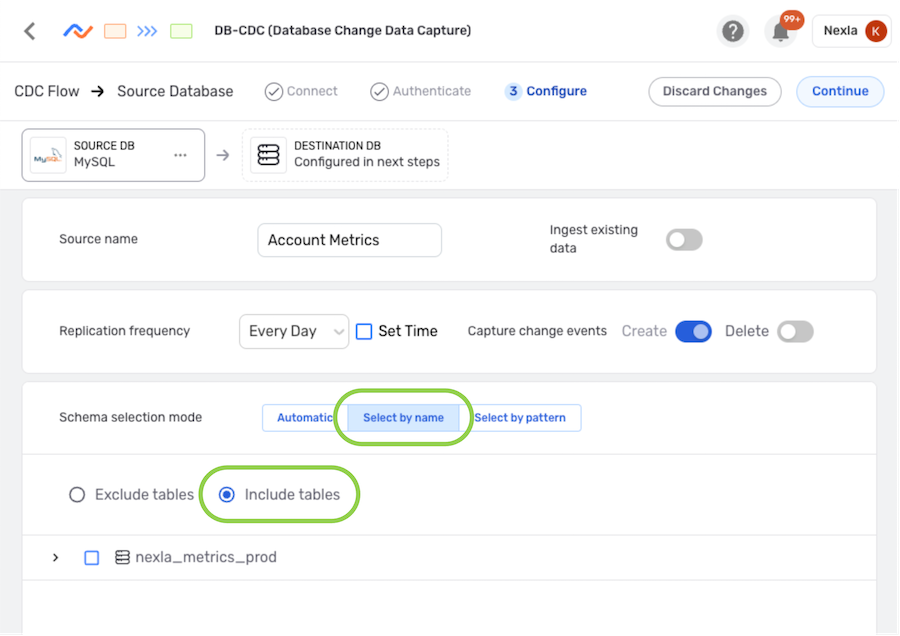
- Click the icon next to the database name to expand the list of tables, and check the box(es) next to the table(s) that should be included in this DB-CDC flow.
Example: Only data & detected changes in the account_metrics_daily table will be
included in the DB-CDC flow
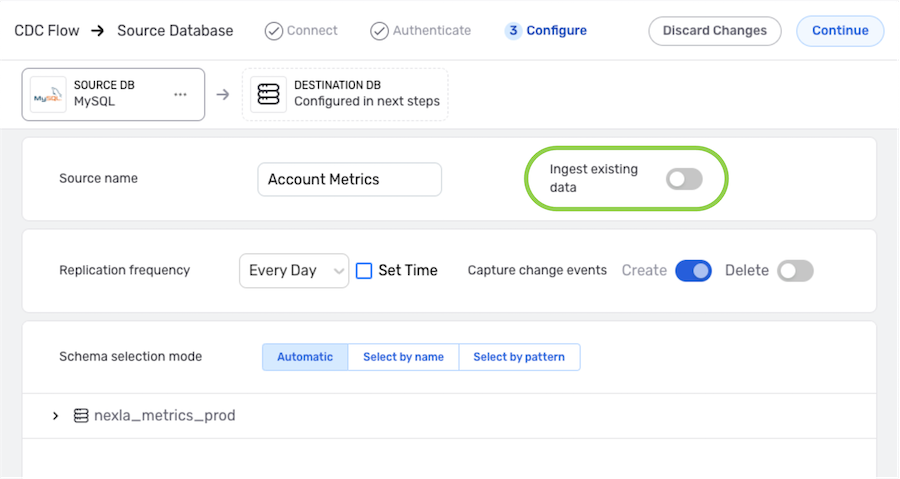
Existing Data
Some use cases require capturing pre-existing data in the source location and reflecting it into the destination, while others need to reflect only newly added data. Nexla can easily be configured for either workflow with a single setting.
▷ To ingest and reflect only data that is added to the source location after the DB-CDC flow is created:
-
Ensure that the Ingest existing data switch is in the off position (gray). This is the default setting, so typically, no change is needed.
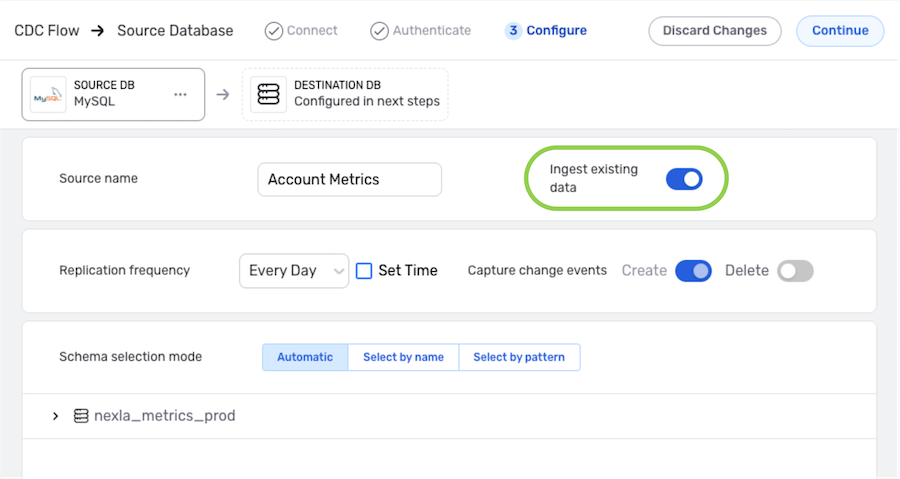
▷ To ingest and reflect all data currently existing in the source location along with newly added data in this DB-CDC flow:
-
Activate the Ingest existing data setting by clicking on the slide switch. Once activated, the switch will turn blue.
Change Capture Settings
In a DB-CDC data flow, Nexla will always capture and reflect data that is newly created in the source location. However, users can choose whether or not data deletions in the source location will also be reflected into the destination.
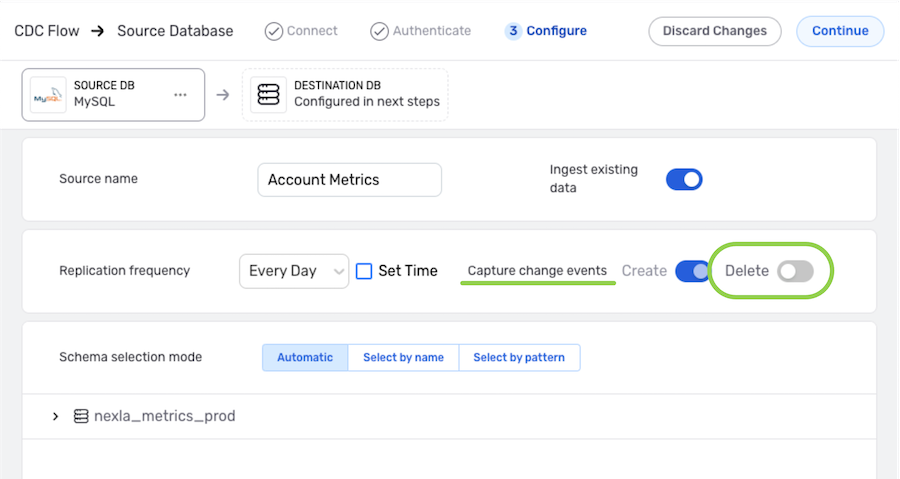
▷ To only reflect newly created data into the destination, without synching any data deletions, in this DB-CDC flow:
-
In the Capture change events settings, ensure that the Delete switch is in the off position (gray). This is the default setting, so typically, no change is needed.
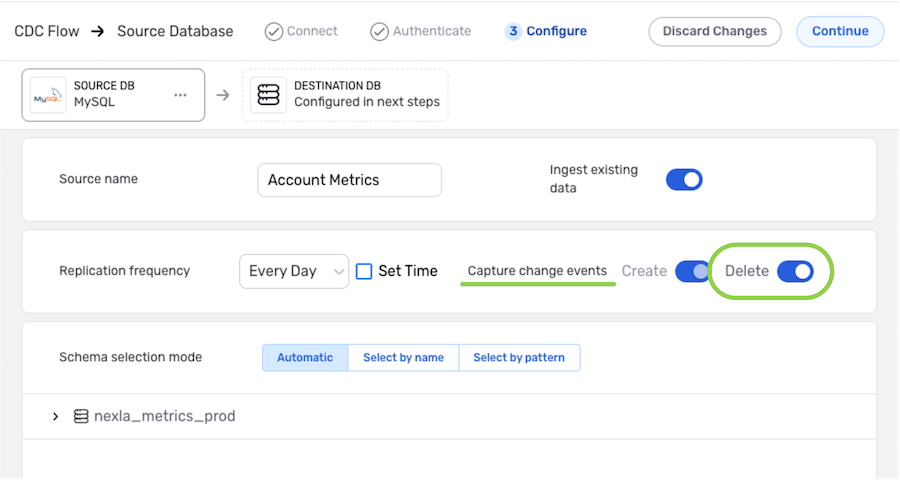
▷ To reflect data deletions in addition to newly created data into the destination in this DB-CDC flow:
-
In the Capture change events settings, activate the Delete setting by clicking on the slide switch. Once activated, the switch will turn blue.
Scheduling
Scan scheduling options can be used to define the frequency at which the data source will be scanned for data changes in a DB-CDC flow. Any data changes identified during a scan will then be replicated into the configured destination.
-
By default, when a new DB-CDC data flow is created, Nexla is configured to scan the source for data changes once every day. To continue with this setting, no further selections are required. Proceed to Save & Activate the Data Source.
-
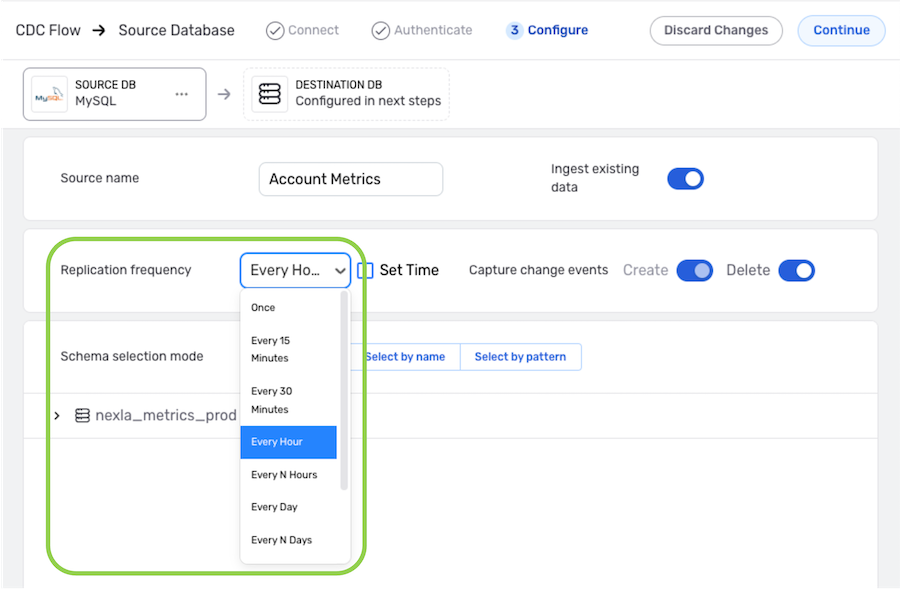
To define how often Nexla should scan the data source for new data changes, select an option from the Replication Frequency pulldown menu.
- When options such as Every N Days or Every N Hours, a secondary pulldown menu will be populated. Select the appropriate value of N from this menu.
-
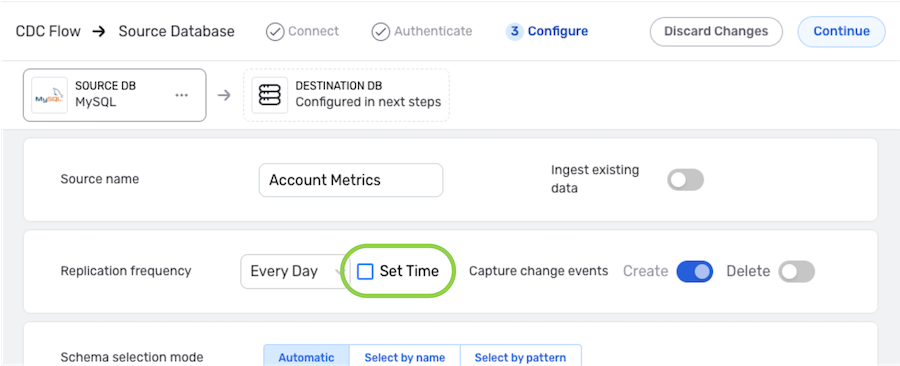
To specify the time at which Nexla should scan the source for new data changes, check the box next to Set Time. Enabling this option will populate new pulldown menus that can be used to define the scan time.
- The scan time menus populated when Set Time is enabled vary according to the selected Replication Frequency.
Step 1:
Step 2:
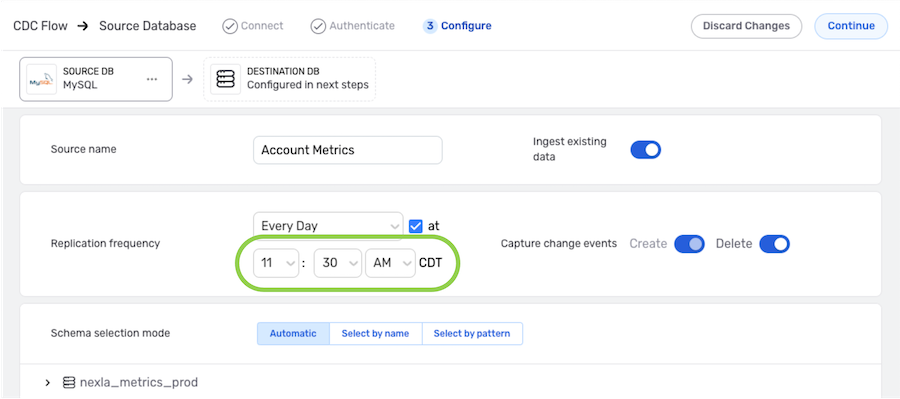
Save & Activate the Data Source
Once all required settings and any desired additional options are configured, click ![]() in the top right corner of the screen to save & activate the data source.
in the top right corner of the screen to save & activate the data source.
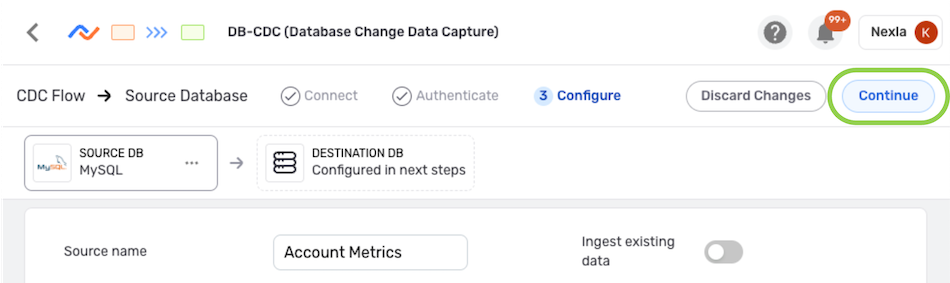
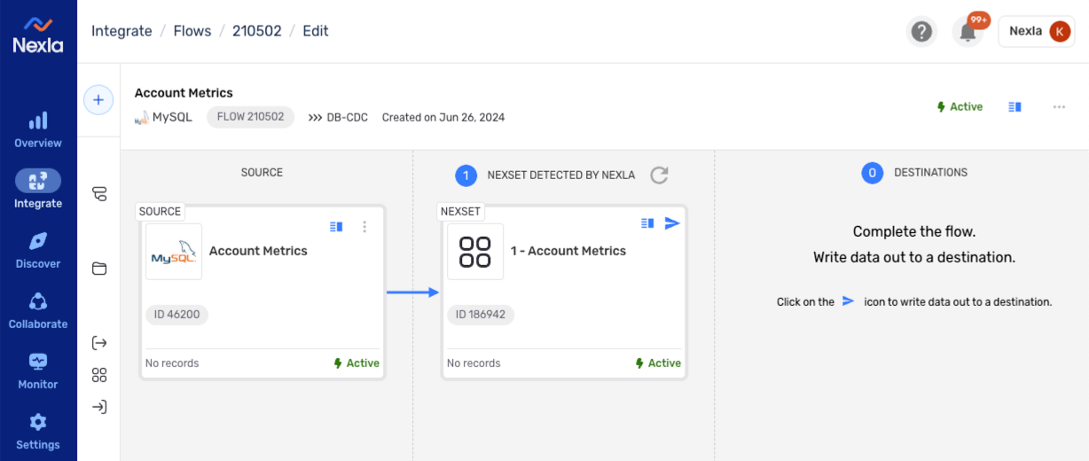
Once the data source is created, Nexla will automatically scan it for data according to the configured settings. Identified data will be organized into a Nexset, which is a logical data product that is immediately ready to be sent to a destination.
New DB-CDC Data Flow with Data Source & Detected Nexset
Spark ETL Data Flows
-
After logging into Nexla, navigate to the Integrate section by selecting
from the platform menu on the left side of the screen. -
Click
at the top of the Integrate toolbar on the left.
- Select Spark ETL from the list of flow types, and click to proceed to data source creation.
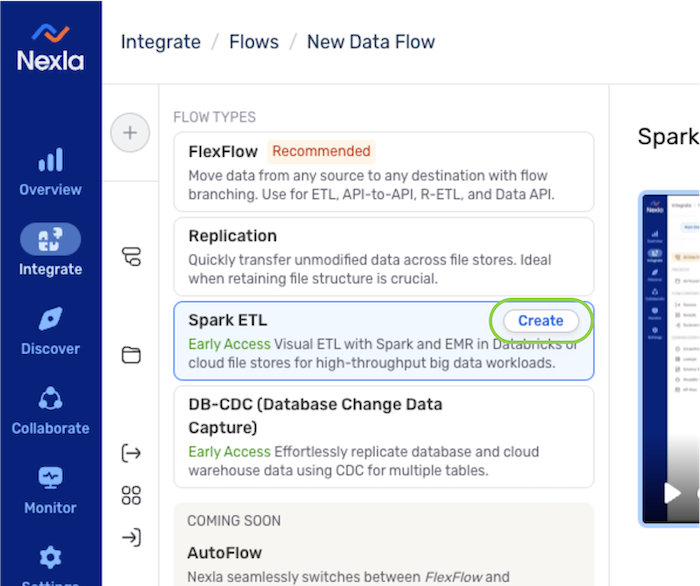
- In the Connect screen, select the connector tile matching the data source type from the list.
Spark ETL data flows are only supported for some of the connectors available in Nexla, and only supported connectors are shown on this screen.
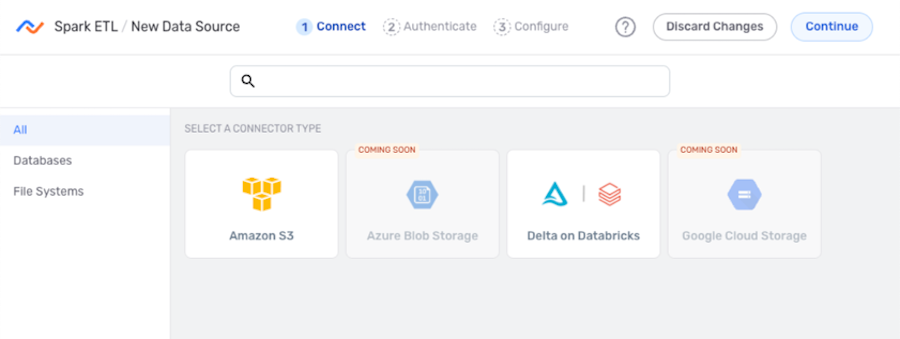
- In the Authenticate screen, follow the instructions below to create or select the credential that will be used to connect to the data source.
To create a new credential:
- Select the Add Credential tile.
- Enter and/or select the required information in the Add New Credential pop-up.
- Once all of the required information has been entered, click at the bottom of the pop-up to save the new credential, and proceed to Configure the Data Source.
To use a previously added or shared credential:
- Select the credential from the list.
- Click in the upper right corner of the screen, and proceed to Configure the Data Source.
Configure the Data Source
- Enter a name for the data source in the Name field.
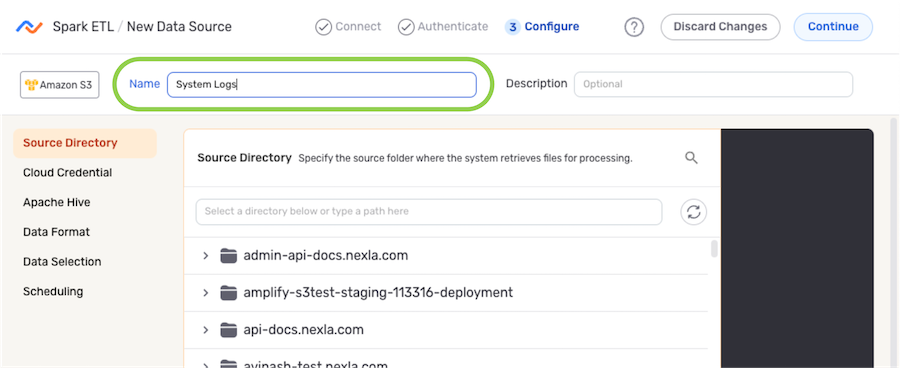
- Optional: Enter a brief description of the data source in the Description field.
Resource descriptions should provide information about the resource purpose, data freshness, etc. that can help the owner and other users efficiently understand and utilize the resource.
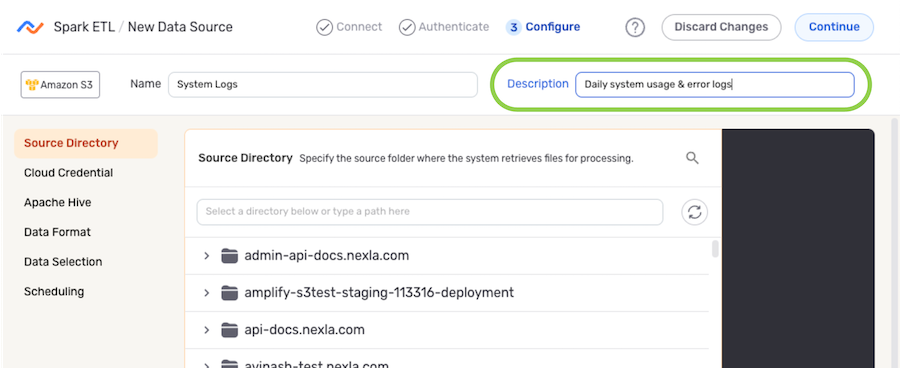
- The subsections below provide information about additional settings available for data sources in Spark ETL flows. Follow the listed instructions to configure each setting for this data source, and then proceed to Save & Activate the Data Source.
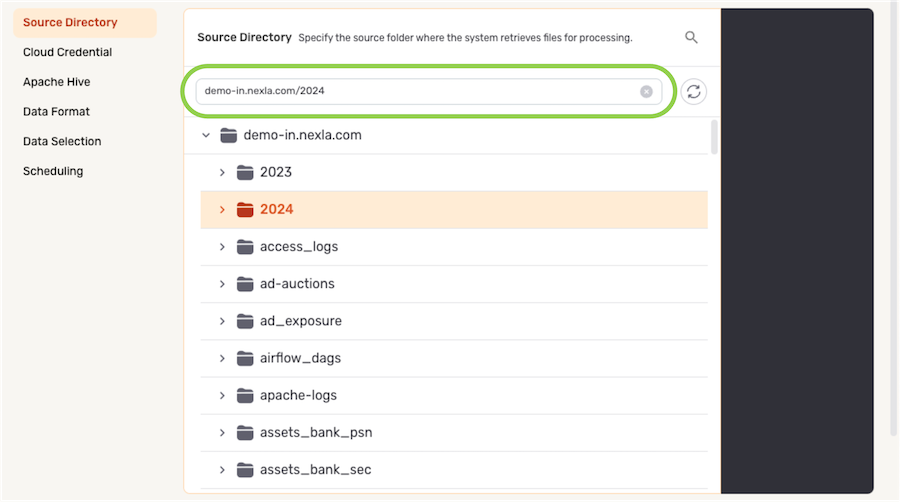
Source Table
In Spark ETL flows, data sources can be configured to ingest all files in the database/Databricks location accessible with the selected credential or only files within a specific folder.
-
Under the Source Table section, navigate to the directory location from which Nexla will read files from this source; then, hover over the listing, and click the
icon to select this location.- To view/select a nested location, click the icon next to a listed folder to expand it.
- To view/select a nested location, click the
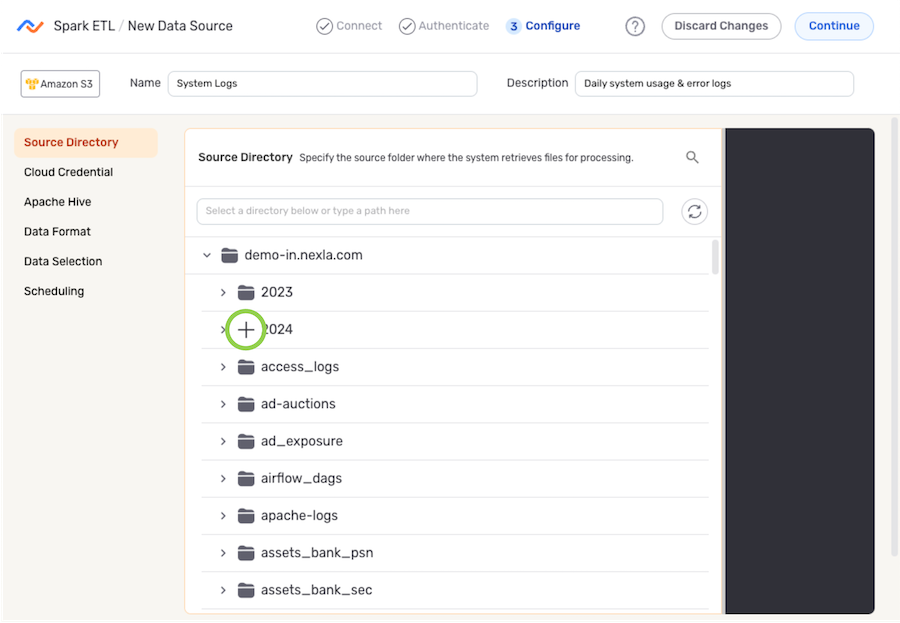
- The selected directory location is displayed at the top of the Source Table section.
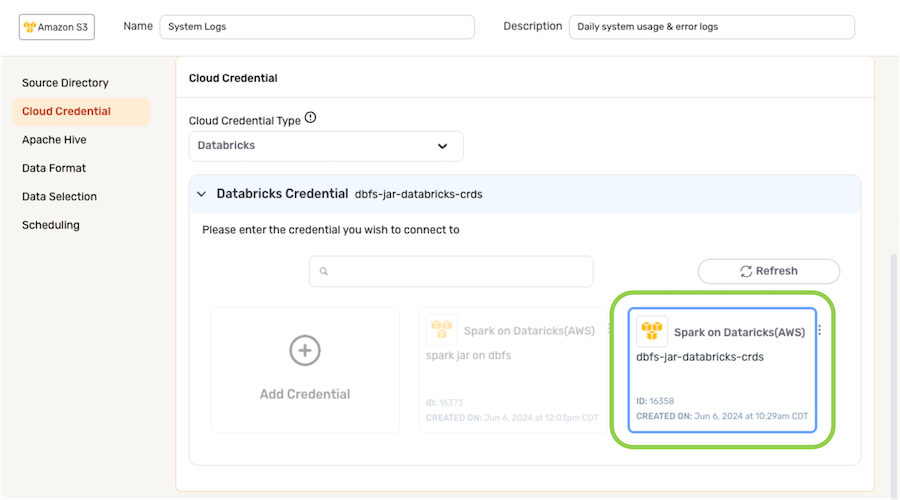
Cloud Credential
- Select the type of cloud credential that will be used to connect to the selected data source location from the Cloud Credential Type pulldown menu.
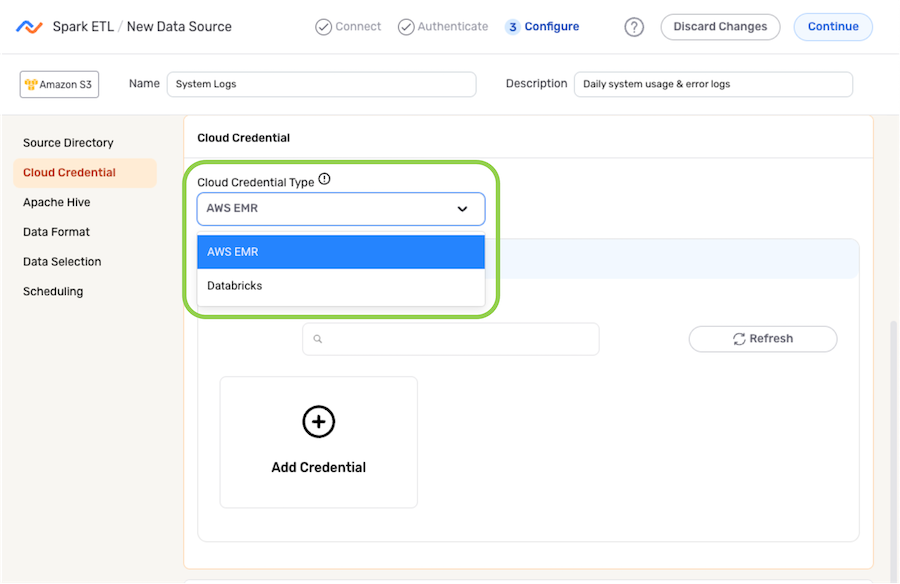
- Add or select the cloud credential that will be used.
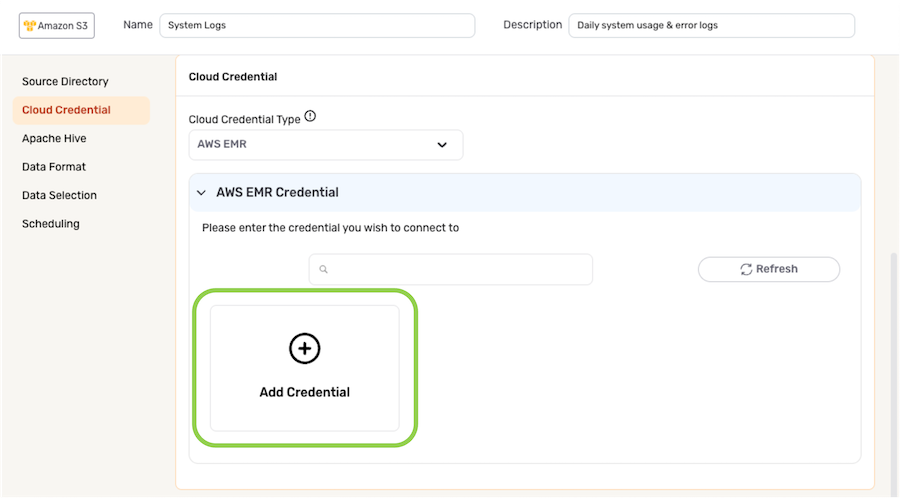
-
To add a new cloud credential:
- Select the Add Credential icon.
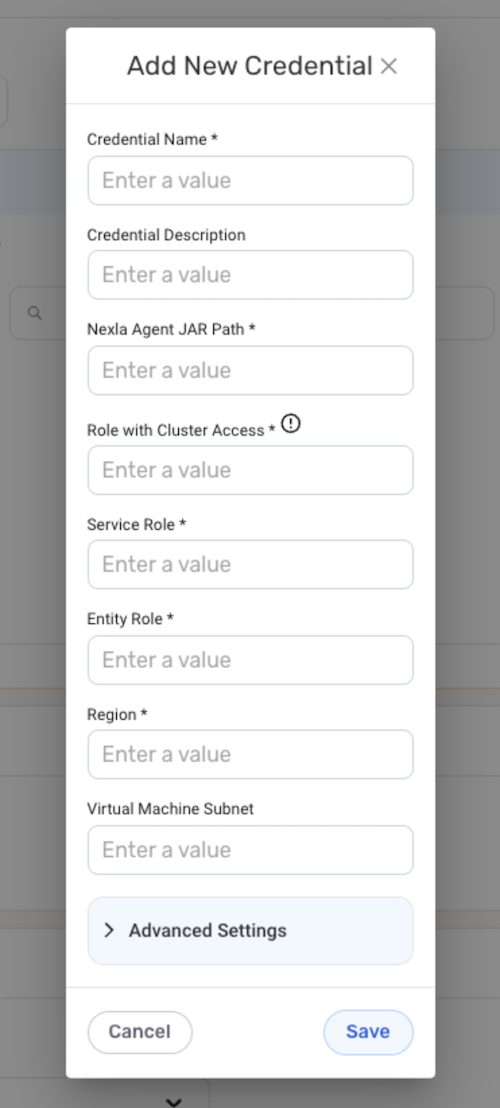
- In the Add New Credential window, enter the required information, and click
 .
.
-
To use an existing cloud credential, select the credential from the list.
Apache Hive
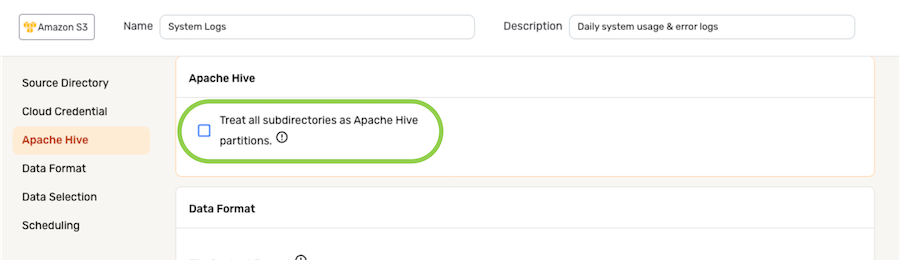
-
To treat all subdirectories detected within the chosen data source location as Apache Hive partitions, check the box next to Treat all subdirectories as Apache Hive partitions.
Data Format
By default, Nexla automatically detects the format of files ingested from data sources and parses the data contained in the files accordingly. Automatic file format detection is recommended for most workflows, including when the source contains files in more than one format.
For more information about Nexla's automatic file format detection, see the Automatic File Format Detection section in Supported File Formats.
For specialized use cases, users can designate a specific incoming file format for a data source in a Spark ETL flow, forcing Nexla to parse all files ingested from the source according to the designated file format.
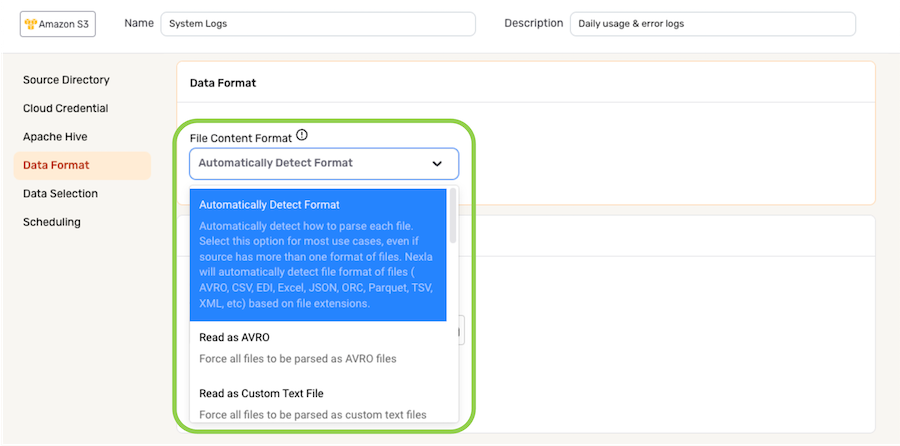
-
To specify the format that will be used to parse files from this source, select the appropriate format from the File Content Format pulldown menu under the Data Format section.
-
Some file formats require additional information, such as delimiter, schema, metadata, and relevant data settings. For instructions on completing these settings, follow the corresponding link below:
Custom Text Files
Compressed ZIP and/or TAR Files
EDI Files
Excel Files
Fixed-Width Files
JSON Files
Log Files
PDF Files
XML Files
Data Selection
When setting up the data source in a Spark ETL flow, Nexla provides configuration options for specifying which data should be ingested from the source, allowing users to customize data ingestion to suit various use cases. Data can be selected for ingestion from file-based storage systems according to file modification dates, naming patterns, and/or subfolder paths.
The settings discussed in this section are located under the Data Selection category.
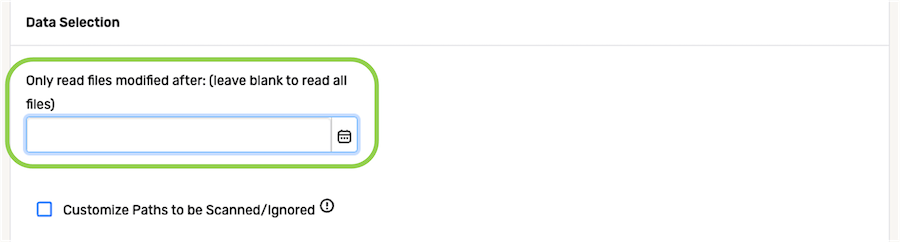
▷ To ingest all files in the selected location:
-
To configure Nexla to ingest all files from the data source, regardless of when the files were added or modified, delete the pre-populated date and time from the Only read files modified after: field, and leave this field blank.
▷ To ingest files according to the most recent modification date:
- When Nexla should only ingest newer or recently modified files from the data source, the platform can be configured to selectively ingest files modified after a specified date and time. To specify the file modification date and time that will be used to select which files should be read from this source, click the
 icon in the Only read files modified after: field under, and select the date from the dropdown calendar.
icon in the Only read files modified after: field under, and select the date from the dropdown calendar.
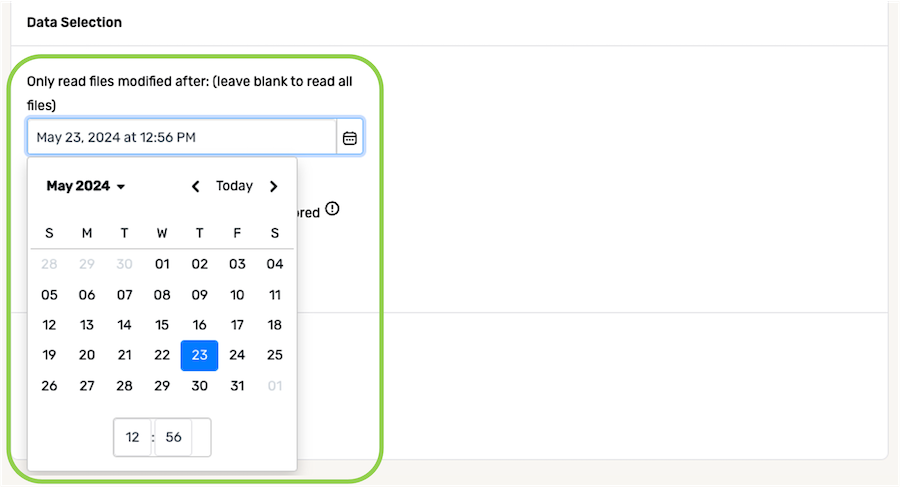
- In the field at the bottom of the calendar, enter the time (in 24-h format) on the selected date that should be referenced when identifying new and/or modified files from the source.
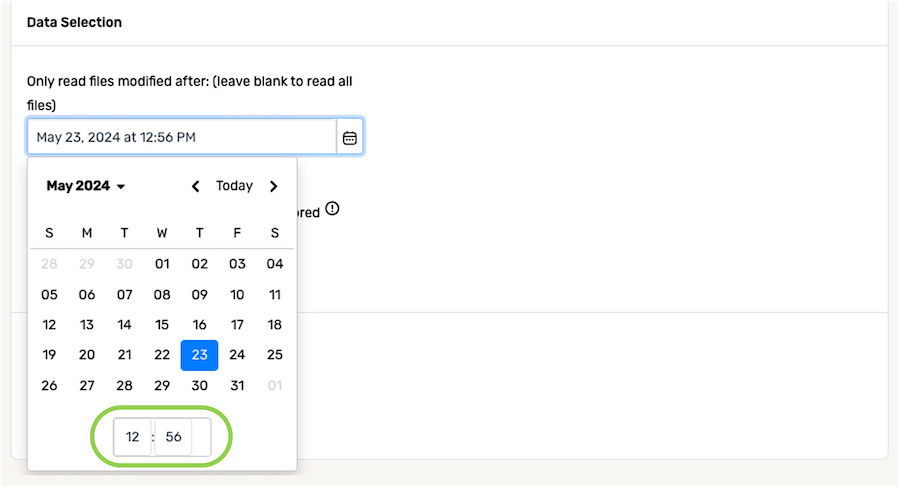
Scheduling
Scan scheduling options can be used to define the frequency at which the data source will be scanned for data changes in a Spark ETL flow. Any data changes identified during a scan will then be replicated into the configured destination.
-
By default, when a new Spark ETL data flow is created, Nexla is configured to scan the source for data changes once every day. To continue with this setting, no further selections are required. Proceed to Save & Activate the Data Source.
-
To define how often Nexla should scan the data source for new data changes, select an option from the Check for Files pulldown menu under the Scheduling section.
- When options such as Every N Days or Every N Hours, a secondary pulldown menu will be populated. Select the appropriate value of N from this menu.
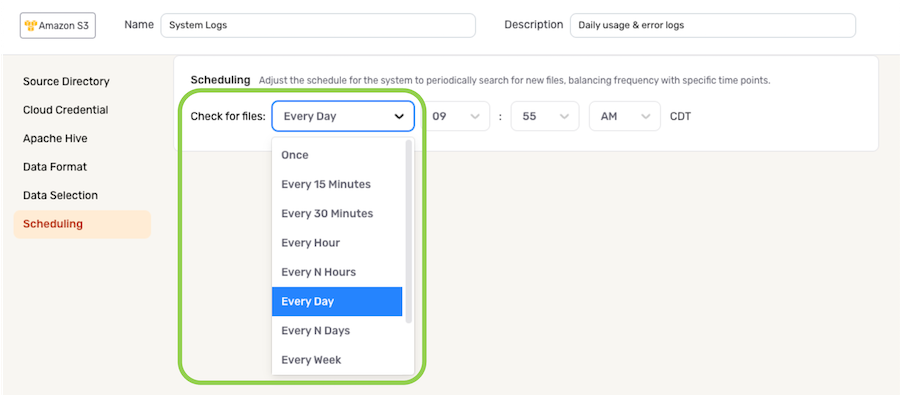
- To specify the time at which Nexla should scan the source for new data changes, use the pulldown menu(s) to the right of the Check For Files menu. These time menus vary according to the selected scan frequency.
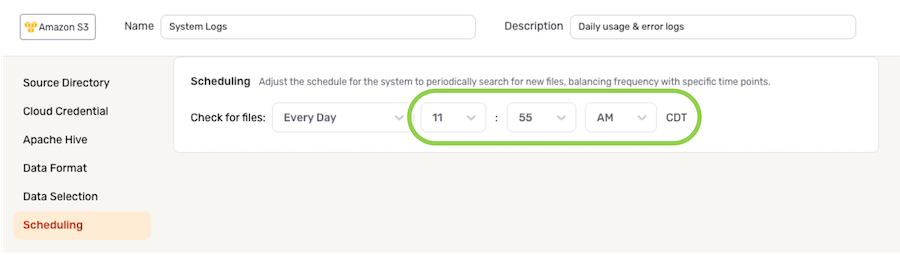
Save & Activate the Data Source
Once all required settings and any desired additional options are configured, click ![]() in the top right corner of the screen to save & activate the data source.
in the top right corner of the screen to save & activate the data source.
Once the data source is created, Nexla will automatically scan it for data according to the configured settings. Identified data will be organized into a Nexset, which is a logical data product that is immediately ready to be sent to a destination.
New Spark ETL Data Flow with Data Source & Detected Nexset
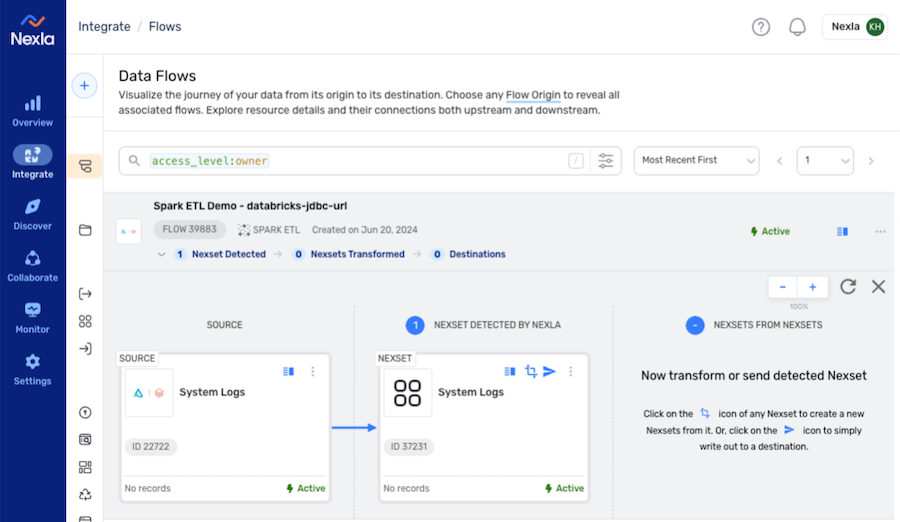
Replication Data Flows
-
After logging into Nexla, navigate to the Integrate section by selecting
from the platform menu on the left side of the screen. -
Click
at the top of the Integrate toolbar on the left.
- Select Replication from the list of flow types, and click to proceed to data source creation.
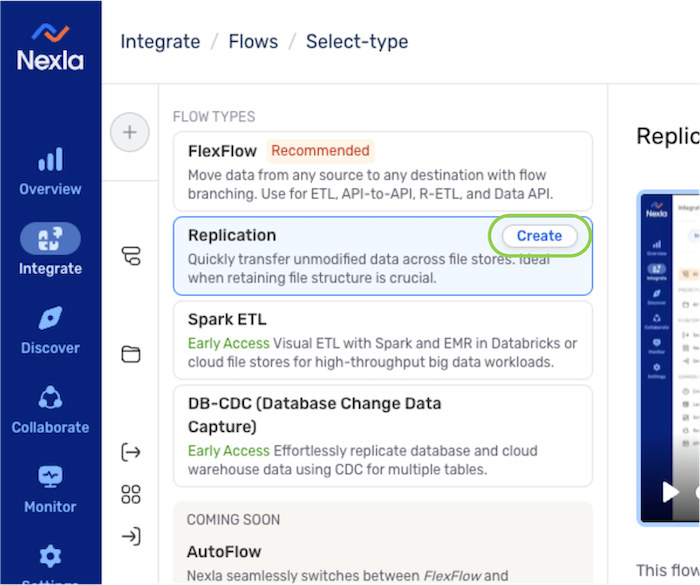
- In the Connect screen, select the connector tile matching the data source type from the list.
Replication data flows are only supported for some of the connectors available in Nexla, and only supported connectors are shown on this screen.
- In the Authenticate screen, follow the instructions below to create or select the credential that will be used to connect to the data source.
To create a new credential:
- Select the Add Credential tile.
- Enter and/or select the required information in the Add New Credential pop-up.
- Once all of the required information has been entered, click at the bottom of the pop-up to save the new credential, and proceed to Configure the Data Source.
To use a previously added or shared credential:
- Select the credential from the list.
- Click in the upper right corner of the screen, and proceed to Configure the Data Source.
Configure the Data Source
- Enter a name for the data source in the Name field.
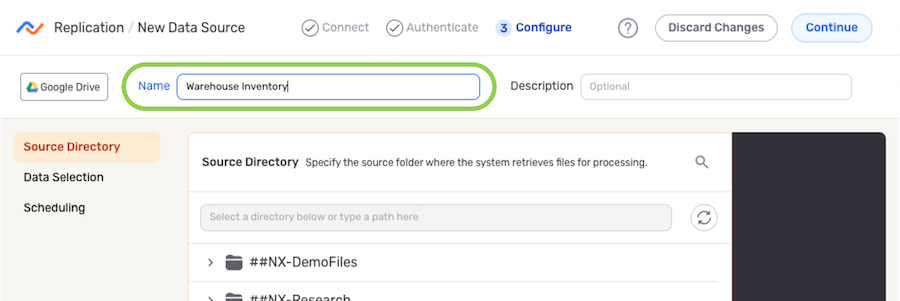
- The subsections below provide information about additional settings available for data sources in Replication flows. Follow the listed instructions to configure each setting for this data source, and then proceed to Save & Activate the Data Source.
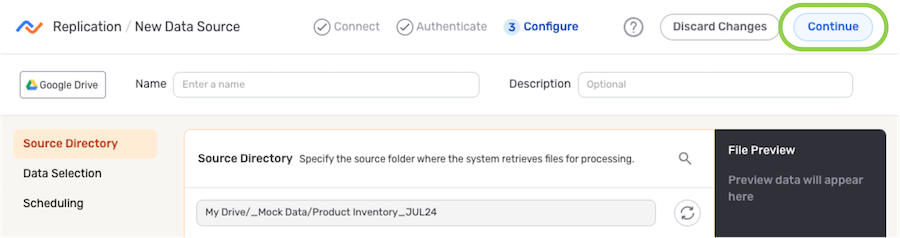
Source Directory
Replication flows can be used to clone an entire directory that is accessible with the selected credential or individual tables within the directory into the destination location.
-
Under the Source Directory section, navigate to the directory location from which Nexla will read files from this source; then, hover over the listing, and click the
icon to select this location.- To view/select a nested location, click the icon next to a listed folder to expand it.
- To view/select a nested location, click the
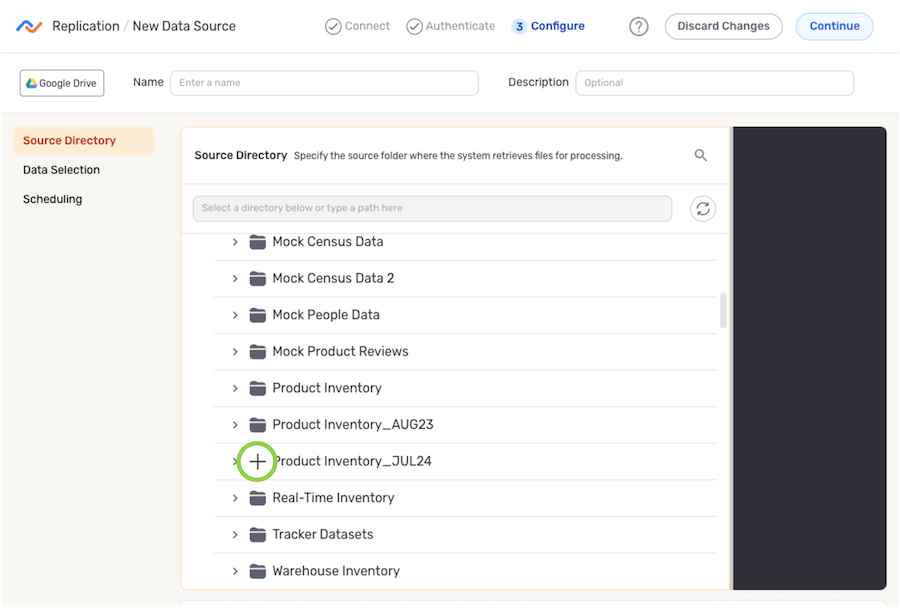
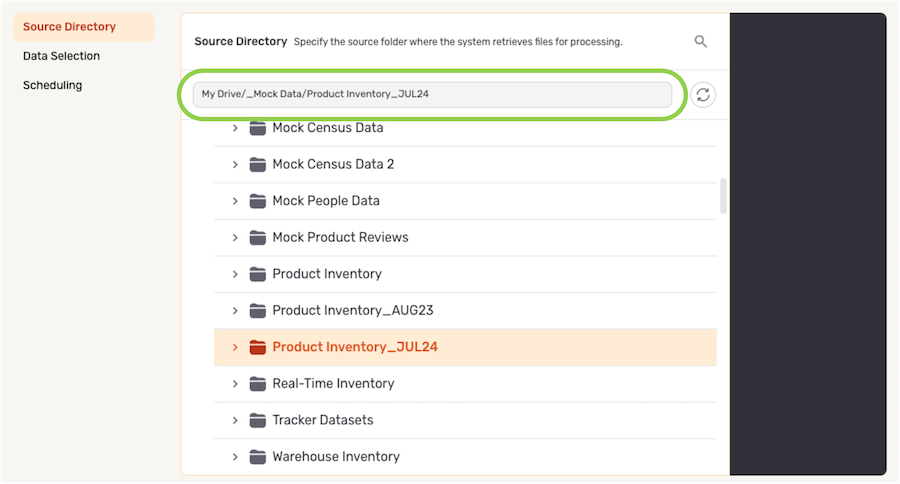
- The selected directory location is displayed at the top of the Source Directory section.
Scheduling
Scan scheduling options can be used to define the frequency at which the source location will be scanned for new or modified data in a Replication flow. Any new or modified data identified during a scan will then be replicated into the configured destination.
-
By default, when a new Replication data flow is created, Nexla is configured to scan the source for data changes once every day. To continue with this setting, no further selections are required. Proceed to Save & Activate the Data Source.
-
To define how often Nexla should scan the data source for new data changes, select an option from the Fetch Data pulldown menu under the Scheduling section.
- When options such as Every N Days or Every N Hours, a secondary pulldown menu will be populated. Select the appropriate value of N from this menu.
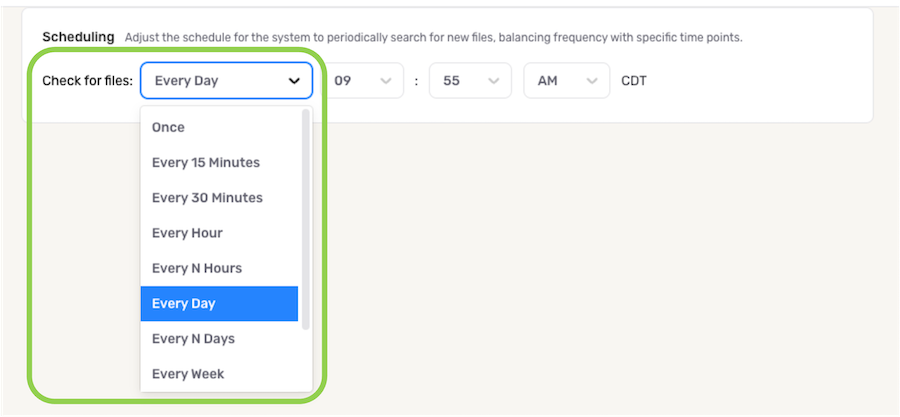
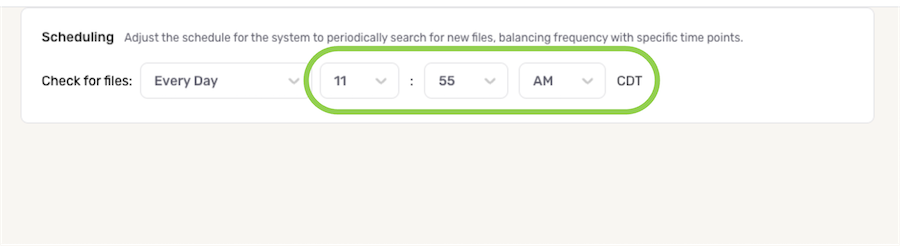
- To specify the time at which Nexla should scan the source for new data changes, use the pulldown menu(s) to the right of the Fetch Data menu. These time menus vary according to the selected scan frequency.
Save & Activate the Data Source
Once all required settings and any desired additional options are configured, click ![]() in the top right corner of the screen to save & activate the data source.
in the top right corner of the screen to save & activate the data source.
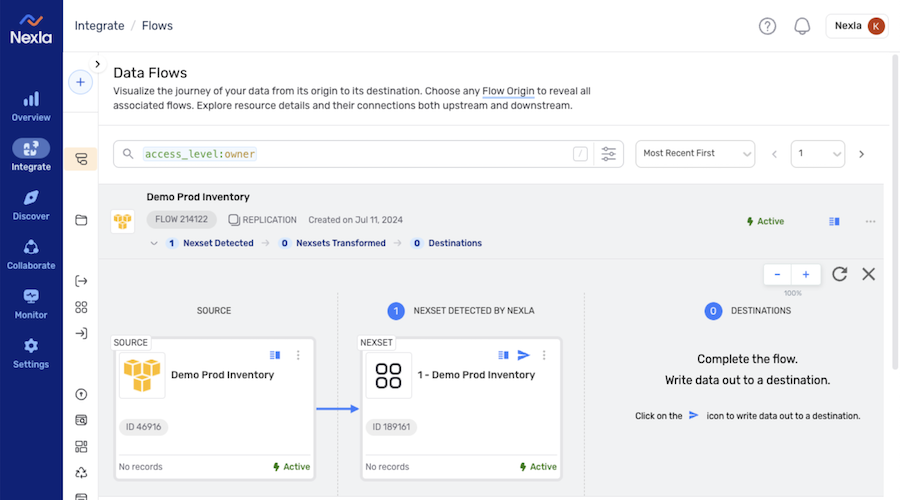
Once the data source is created, Nexla will automatically scan it for data according to the configured settings. Identified data will be organized into a Nexset, which is a logical data product that is immediately ready to be sent to a destination.
New Replication Data Flow with Data Source & Detected Nexset
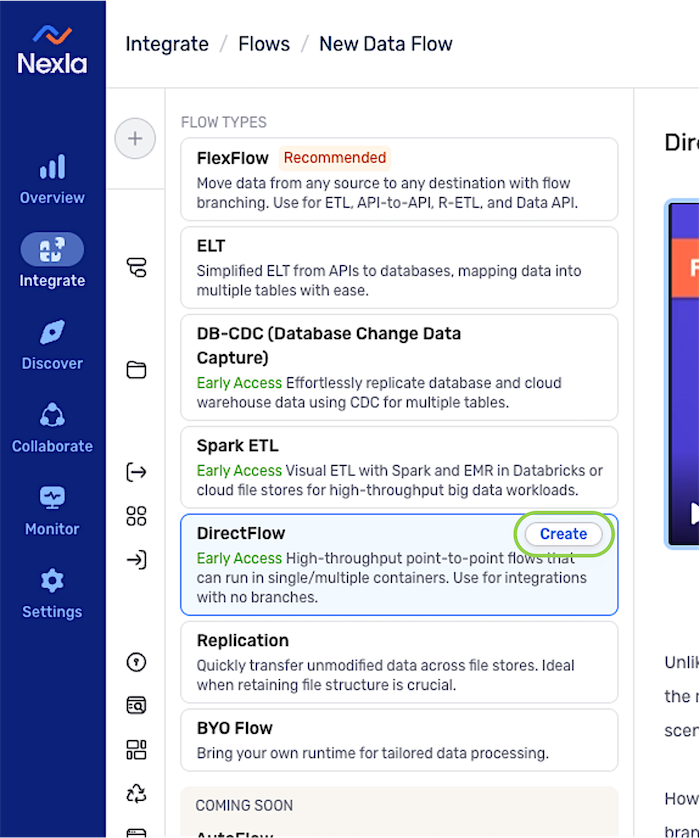
DirectFlow Data Flows
-
After logging into Nexla, navigate to the Integrate section by selecting
from the platform menu on the left side of the screen. -
Click
at the top of the Integrate toolbar on the left.
- Select DirectFlow from the list of flow types, and click to proceed to data source creation.
Configure the Data Source
In Nexla, database & data warehouse data sources can be configured using either Table Mode or Query Mode.
This section provides instructions for configuring the source using Table Mode, which allows users to specify which data should be ingested from the database source through a simple selection method. This mode is equivalent to running a simple, optimized SELECT operation on any database/data warehouse table.
Query Mode allows users to enter a query to selectively fetch specific data from the source. This mode provides a free-form query editor that can be used to write queries using the syntax and convention supported by the underlying database. Queries of any complexity level can be executed, as long as they adhere to the supported syntax.
To learn how to configure database & data warehouse sources using Query Mode, see the Query Mode section in Database Sources - Table Mode & Query Mode.
- In the Connect screen, select the connector tile matching the desired data source type from the list.
-
DirectFlow data flows do not support streaming data sources, such as webhooks, Kafka sources, and other realtime sources. Only supported connectors are shown in the Connect screen.
-
To create a data flow with a data source type not available in this screen, use the FlexFlow flow type or one of Nexla's other flow types.
-

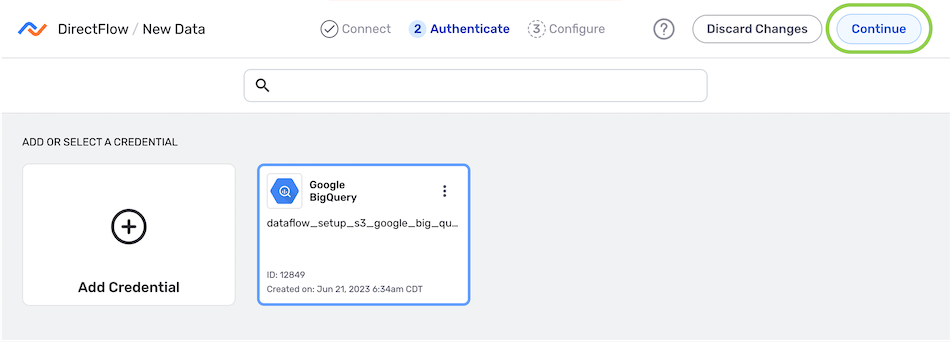
- In the Authenticate screen, select or create the credential that will be used to connect to the data source, and click
 . Detailed information about credential creation for specific sources can be found on the Connectors page.
. Detailed information about credential creation for specific sources can be found on the Connectors page.
- Enter a name for the data source in the Name field.
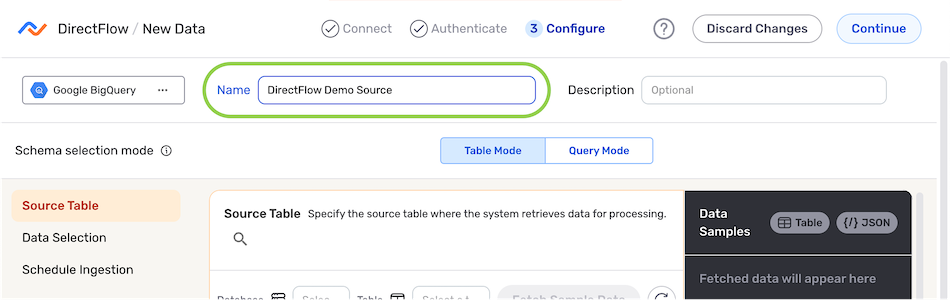
-
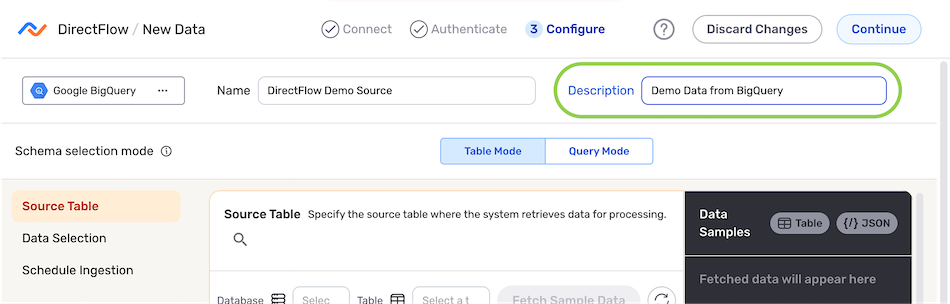
Optional: Enter a description of the data source in the Description field.
Resource DescriptionsResource descriptions should provide information about the resource purpose, data freshness, etc. that can help the owner and other users efficiently understand and utilize the resource.
Data Selection (Full/Partial Data Loading)
When setting up a database/data warehouse source in a data flow, Nexla provides configuration options for specifying which data should be ingested from the source location, allowing users to customize data ingestion to suit various use cases. Partial data loading from the selected location can be configured using record IDs and/or timestamps using the table scan modes available under the Data Selection category.
▷ Full data loading from the selected location:
-
To configure Nexla to ingest all data from the selected database location, select Read the whole table from the Table Scan Mode menu.
▷ Partial data loading according to a record ID:
- To configure Nexla to ingest data from the selected location by beginning at a specified record ID, select Start reading from a specific ID from the Table Scan Mode menu.
- Select the column containing the ID that will be used to execute partial data loading from the ID Column pulldown menu.
The ID Column must be a numeric column.
- Enter the ID value from which Nexla should start ingesting data in the Starting ID field.
The Starting ID must be an value located in the ID Column selected in the previous step.
▷ Partial data loading according to a timestamp:
- To configure Nexla to ingest data from the selected location by beginning at a specified timestamp, select Start reading from a specific timestamp from the Table Scan Mode menu.
- Select the column containing the timestamp that will be used to execute partial data loading from the Timestamp Column pulldown menu.
The Timestamp Column must be a datetime column.
- Enter the timestamp value from which Nexla should start ingesting data in the Starting Timestamp field.
The Starting Timestamp must be a UNIX epoch (milliseconds)- or ISO-formatted date value—e.g., 2016-01-01T12:13:14. This timestamp must also be a value located in the Timestamp Column selected in the previous step.
▷ Partial data loading according to both a record ID & a timestamp:
- To configure Nexla to ingest data from the selected location by beginning at a specified ID & timestamp, select Start reading from a specific ID and timestamp from the Table Scan Mode menu.
- Select the column containing the ID that will be used to execute partial data loading from the ID Column pulldown menu.
The ID Column must be a numeric column.
- Enter the ID value from which Nexla should start ingesting data in the Starting ID field.
The Starting ID must be an value located in the ID Column selected in the previous step.
- Select the column containing the timestamp that will be used to execute partial data loading from the Timestamp Column pulldown menu.
The Timestamp Column must be a datetime column.
- Enter the timestamp value from which Nexla should start ingesting data in the Starting Timestamp field.
The Starting Timestamp must be a UNIX epoch (milliseconds)- or ISO-formatted date value—e.g., 2016-01-01T12:13:14. This timestamp must also be a value located in the Timestamp Column selected in the previous step.
Scheduling
Scan scheduling options can be used to define the frequency at which the selected location will be scanned for new data and/or changes in a data flow. Any new data/changes identified during a scan will then be ingested into the flow.
-
By default, when a new data flow is created, Nexla is configured to scan the source for data changes once every day. To continue with this setting, no further selections are required. Proceed to Save & Activate the Data Source.
-
To define how often Nexla should scan the data source for new data changes, select an option from the Fetch Data pulldown menu under the Schedule Ingestion section.
- When options such as Every N Days or Every N Hours, a secondary pulldown menu will be populated. Select the appropriate value of N from this menu.
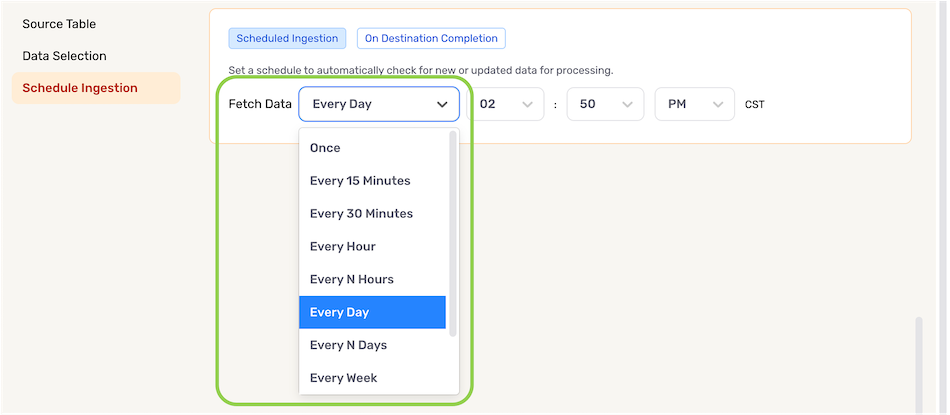
- To specify the time at which Nexla should scan the source for new data changes, use the pulldown menu(s) to the right of the Fetch Data menu. These time menus vary according to the selected scan frequency.

Save & Activate the Data Source
After configuring all required settings and any desired additional options, click ![]() in the top right corner of the screen to save & activate the data source.
in the top right corner of the screen to save & activate the data source.
- Once the data source is created, Nexla will automatically scan it for data according to the configured settings. Identified data will be organized into a Nexset, which is a logical data product that is immediately ready to be sent to a destination.
How Nexla Organizes Data
When Nexla ingests data from a source, the platform intelligently analyzes the structure of the data to organize it into one or more Nexsets.
If a location containing multiple tables is selected when configuring a data source from a database/data warehouse, Nexla will examine the differences between the ingested tables. The platform will then create Nexsets containing the ingested data based on the level of overlap between records and options selected during data source creation.
After the initial data ingestion cycle, Nexla will repeat the process of comparing the structure and composition of newly ingested data to any existing Nexsets during subsequent cycles. Similar data will be added to existing Nexsets, while significantly different data will be organized into a new Nexset.
Ingestion of Newly Added or Modified Data
Once a data source has been created in Nexla, whether from a database/data warehouse or any other type of service, the platform will scan the source at regular intervals according to the configured scheduling options. When Nexla detects new data during a scan, it will automatically ingest and process the new data.
Nexla also tracks the number of rows of data that have been ingested from each table. Therefore, when additional rows of data are added to a previously ingested table, the platform will automatically ingest and process the added data.
Nexla reads and processes data from a source according to the configured schedule, but the platform will wait for a period of inactivity at the source before executing a scan.
3. Destinations: Sending Data to Databases/Data Warehouses
Nexla's bi-directional connectors allow data to flow both to and from any location, making it simple to set up up a data flow that sends data to a database or data warehouse.
Follow the instructions below to create a database/data warehouse destination in any data flow.
To view all accessible Nexsets within their associated data flows:
Navigate to the Integrate section, and select All Data Flows from the menu on the left. Then, click on any listed data flow to view all detected and transformed Nexsets that it contains.
To view a list of all Nexsets accessible to the Nexla user account:
Navigate to the Integrate section, and select Nexsets from the menu on the left to open the Nexsets screen.
- Locate the Nexset that will be sent to the database destination, click the
 icon on the Nexset to open the resource menu, and select Send to Destination.
icon on the Nexset to open the resource menu, and select Send to Destination.
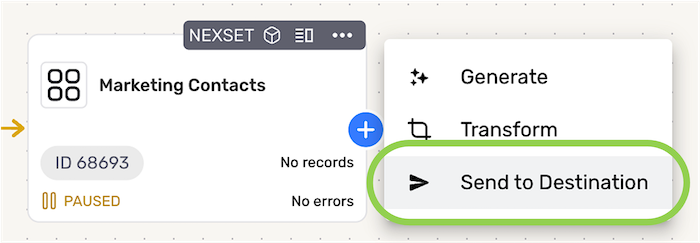
- In the Connect screen, select the connector tile matching the data destination type from the list.

-
In the Authenticate screen, select or create the credential that will be used to connect to the data source, and click the Continue button. For detailed information about creating credentials for specific destinations, see the Connectors pages.
-
Each of Nexla's flow types includes destination configuration options that are specific to the flow type. Click the link corresponding to your flow type in the list below to learn how to configure the destination and complete the destination setup process.
▷ FlexFlow Data Flows
▷ DB-CDC Data Flows
▷ Spark ETL Data Flows
▷ Replication Data Flows
▷ DirectFlow Data Flows
▷ ELT Data Flows
FlexFlow Data Flows
- Enter a name for the destination in the Name field.

- Optional: Enter a brief description of the destination in the Description field.
Resource descriptions should provide information about the resource purpose, data freshness, etc. that can help the owner and other users efficiently understand and utilize the resource.
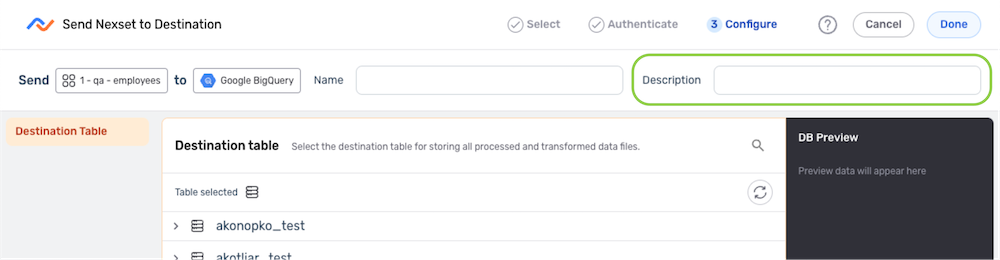
Configure the Destination
- FlexFlow data flows can be used to send the Nexset data to an existing database table, or users can create and send the data to a new table in the database. Instructions for configuring each of these options are provided below.
Send Data to an Existing Table
-
Under the Destination Table settings category, locate the database table to which Nexla should send the data. Expand databases and tables as necessary by clicking the
icon next to a directory location. -
Select the table to which the data will be sent by hovering over it and clicking the
icon.
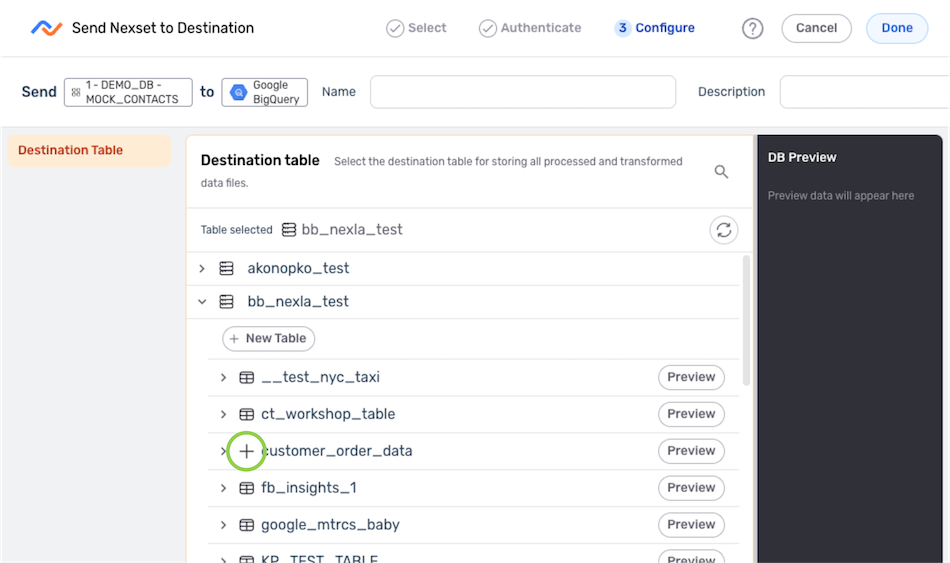
- Continue to the Update Mode settings.
Create a New Table
-
Locate the database table to which Nexla should send the data. Expand databases and tables as necessary by clicking the
icon next to a directory location. -
Click
 below the database in which a new table should be created.
below the database in which a new table should be created.
To create and send the data to a new table, the credential used to connect to the destination must have permissions to create tables in the database. If these permissions are removed after the data flow is created, all database updates associated with the flow will be stopped, and the user will receive a notification in Nexla.
- Under the Format Table settings category, enter a name for the new table in the Table Name field.
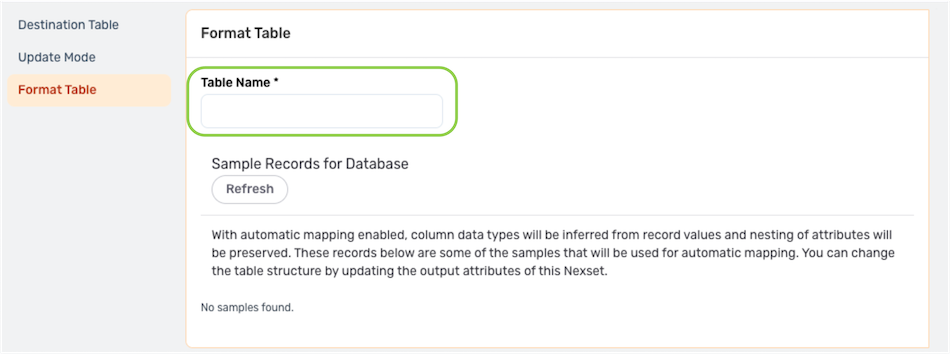
- Continue to the Update Mode settings.
Update Mode
Nexla can be configured to insert or upsert the Nexset data into the database table.
-
Insert – When this update mode is selected, the Nexset record attributes will be inserted into the destination table as new columns.
-
Upsert – When this update mode is selected, the values in each Nexset record attribute corresponding to an existing column in the destination table will be used to update that column, and any record attributes that do not correspond to an existing column will be inserted as new columns.
▷ To use the Insert update mode:
- Under the Update Mode settings category, select Insert from the pulldown menu.
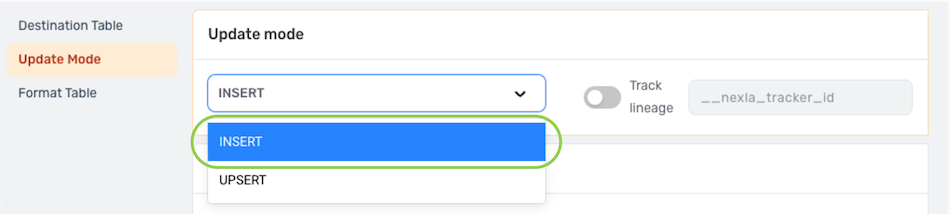
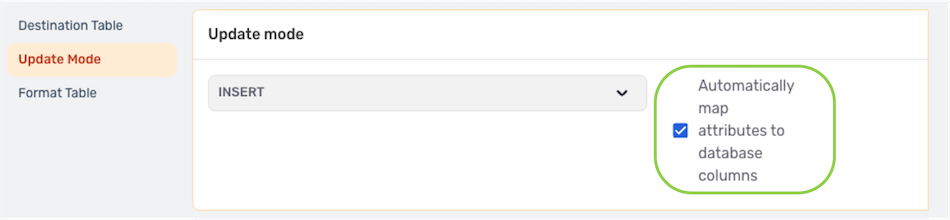
- When using Insert mode, Nexla can be configured to automatically map the Nexset attributes to existing columns in the destination table. To use this option, check the box next to Automatically map attributes to database columns; or, to manually map the Nexset attributes to table columns, uncheck this box to disable automatic mapping.
-
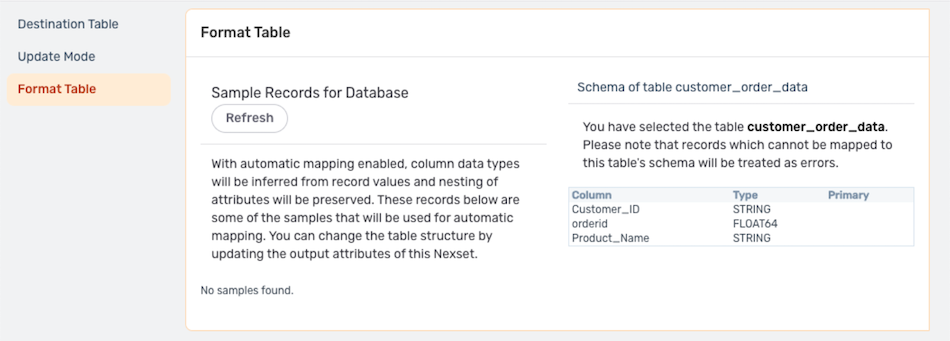
When automatic column mapping is enabled, the schema of the selected destination table is shown under the Format Table settings category. Linked attributes, column names, and data types cannot be changed as described in the Column Mapping section below; instead, edit or transform the Nexset to make any needed changes.
- Continue to the Column Mapping settings.
▷ To use the Upsert update mode:
- Under the Update Mode settings category, select Upsert from the pulldown menu.
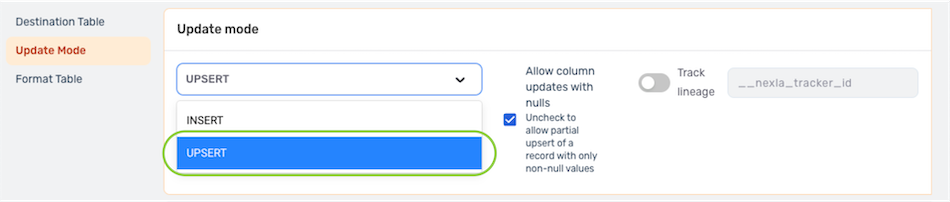
- By default, Nexla is configured to allow destination table columns to be updated with null values when using Upsert mode. To omit null Nexset record attribute values from the upsert and allow the Nexset records to be partially upserted, disable this option by unchecking the box next to Allow column updates with nulls.
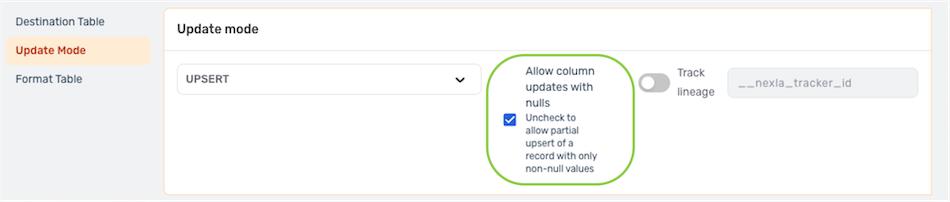
- Under the Format Table settings category, select the attribute that will be used as the primary key by checking the box under Primary to the right of that attribute.
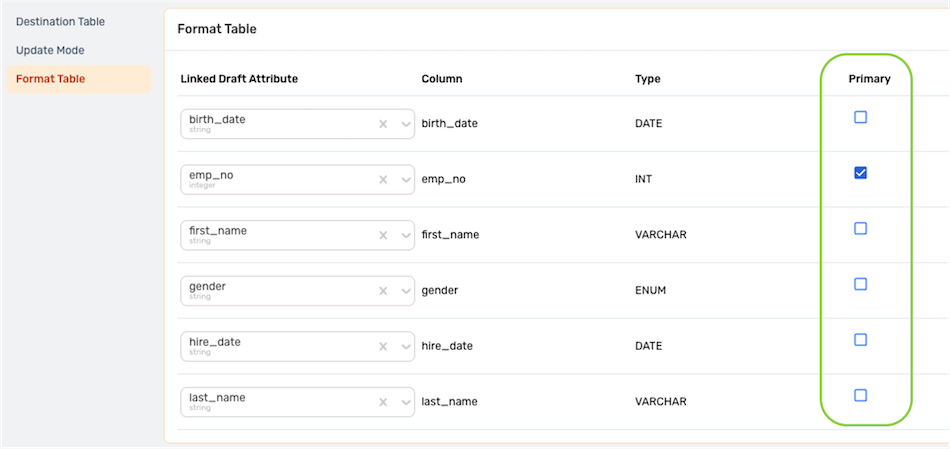
- Continue to the Column Mapping settings.
Column Mapping
The Nexset attributes are mapped to columns in the destination table under the Format Table settings category.
▷ Existing Table:
When sending data to an existing table, Nexla will automatically provide a draft column map with Nexset attributes linked to matching destination table columns. Linked draft attributes can be changed and/or selected using the pulldown menus.
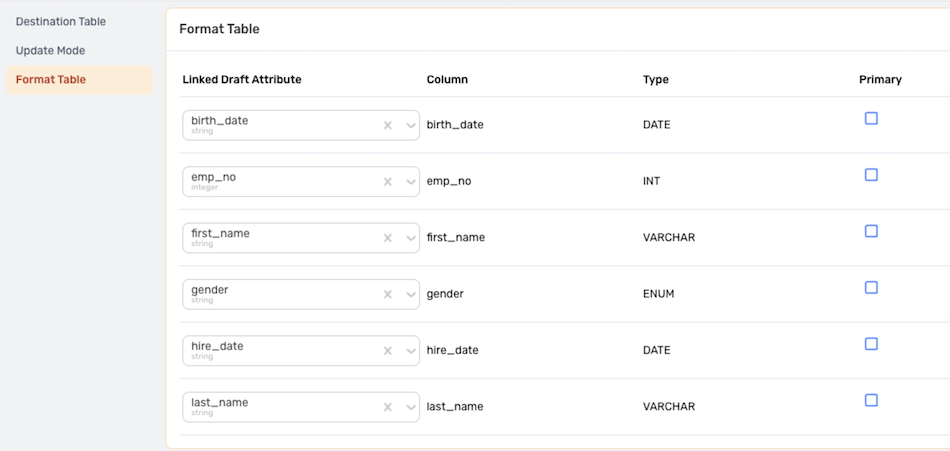
▷ New Table:
When the destination is a new table, the draft column map will be populated with suggested column names and data types. Suggested column names can be edited directly in the field, and data types can be changed using the pulldown menu.
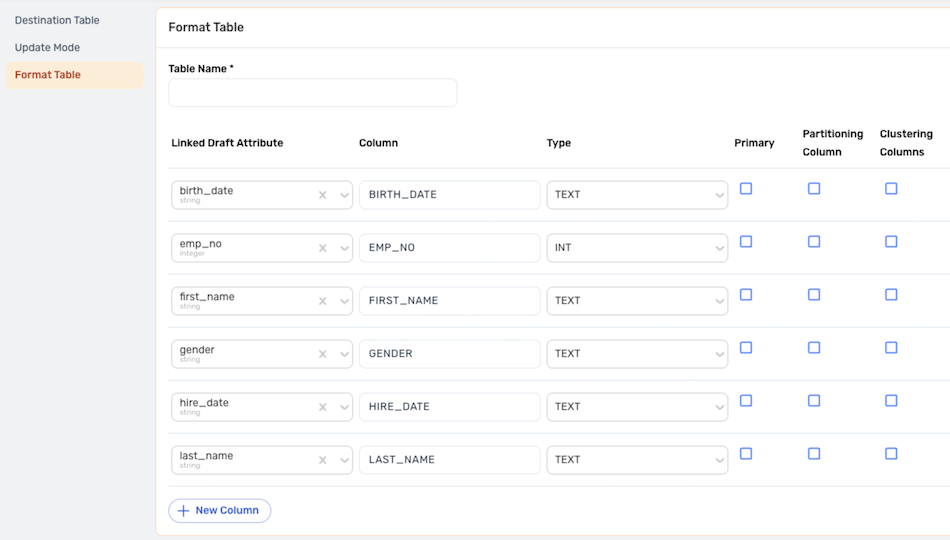
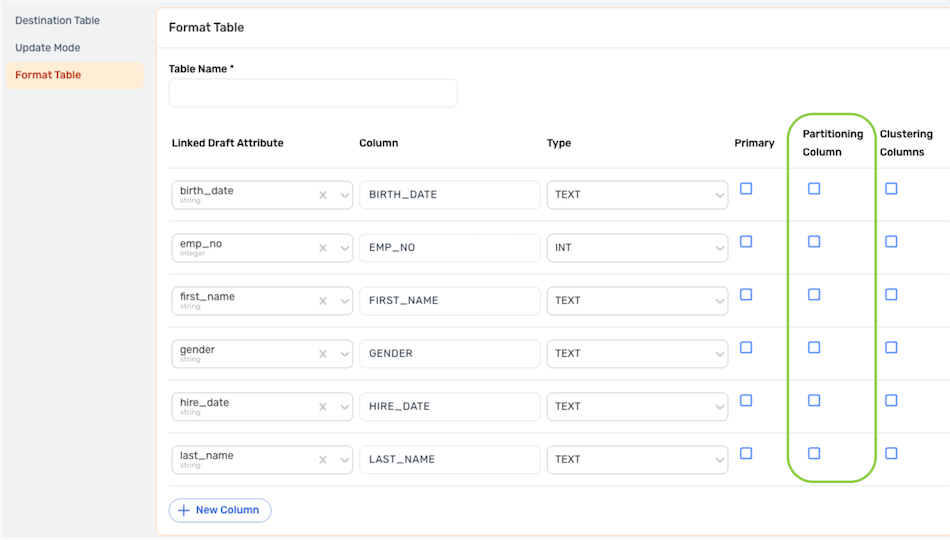
Table Partitioning
For partitioned database tables, select the column containing the partitioning value by checking the box to the right of the column under Partitioning Column
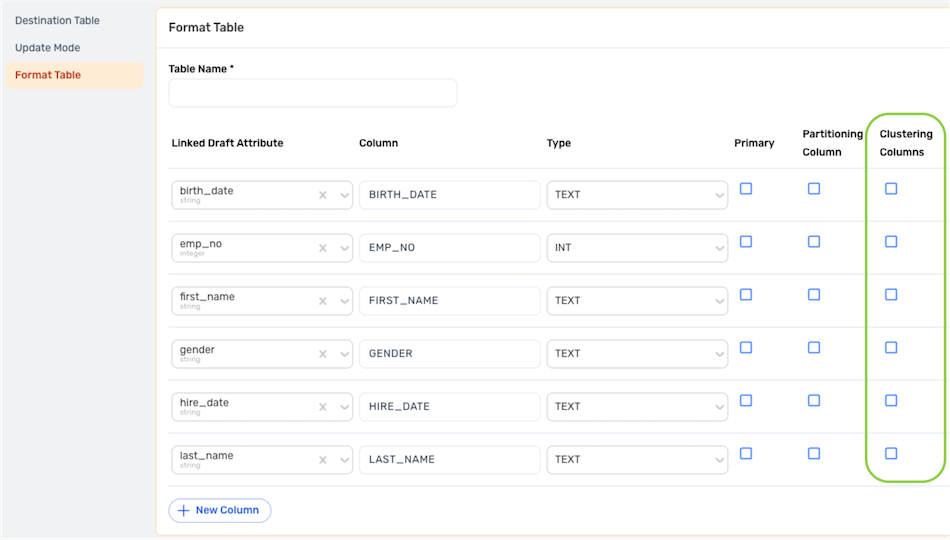
Clustering
For partitioned database tables that use clustering, select the column(s) containing the values used to determine clustering by checking the box(es) to the right of the column(s) under Clustering Columns.
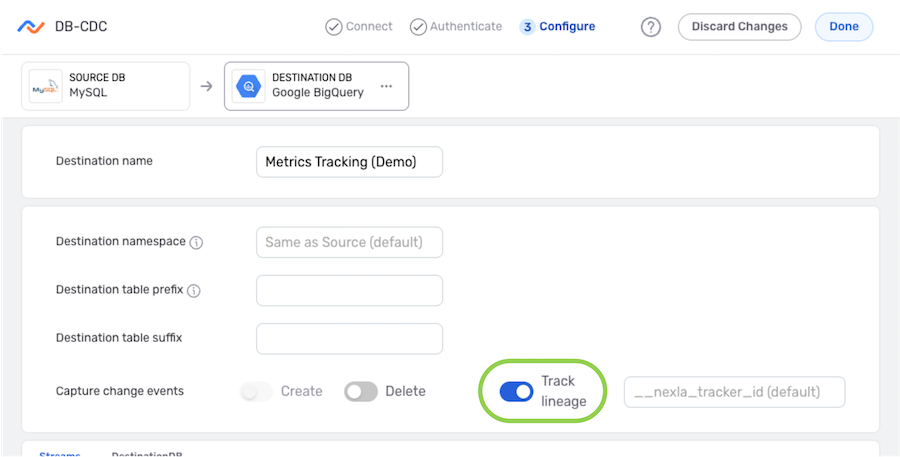
Record Lineage Tracking
Nexla provides the option to trace the lineage of records sent to the database table. This lineage includes the origin of the record data, all applied transformations or changes, and all destinations to which the record data has been sent over time.
- To enable record lineage tracking, click on the Track Lineage slide switch. Once activated, the switch will turn blue.

- Enter the tracker name in the Track Lineage text field. Nexla will include an attribute with the name entered in this field. This attribute will be assigned a unique value for each record written to the destination.

Save & Activate the Destination
- Once all required settings and any desired additional options are configured, click
 in the top right corner of the screen to save the data destination.
in the top right corner of the screen to save the data destination.
Data will not begin to flow into the destination until it is activated in the following step.
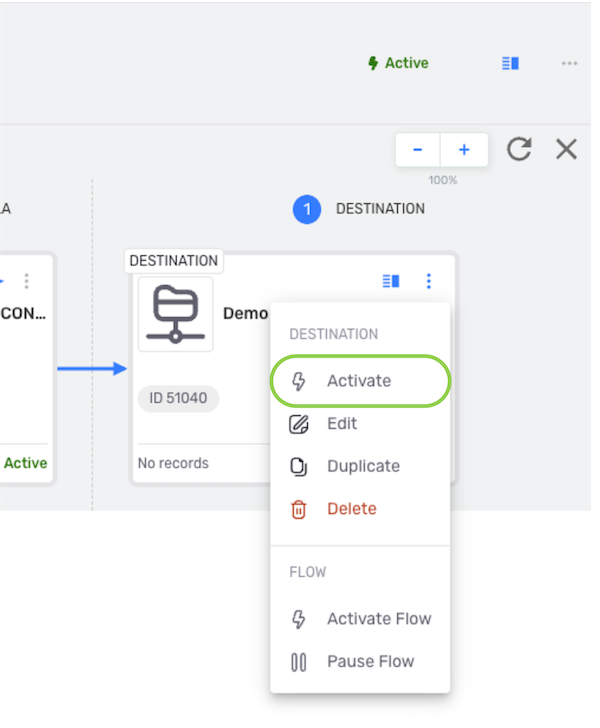
- To activate the destination, click the
 icon on the destination, and select
icon on the destination, and select  from the dropdown menu.
from the dropdown menu.
DB-CDC Data Flows
Configure the Destination
- Enter a name for the destination in the Destination Name field.
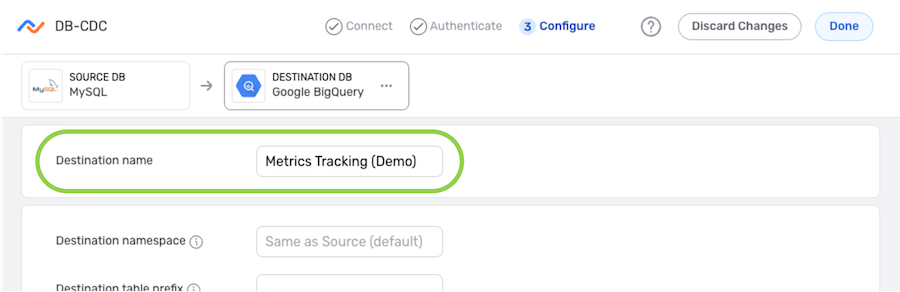
Namespace
In a DB-DCD data flow, users can designate the destination namespace to which data will be sent.
-
By default, Nexla will send the data to the namespace with a title matching the destination name entered in Step 3 above; or, if no matching namespace title exists in the destination, Nexla will create a new namespace with the entered title. To use this default setting, no further action is required.
-
To specify the namespace to which data will be sent in this flow, enter the namespace title in the Destination Namespace field.
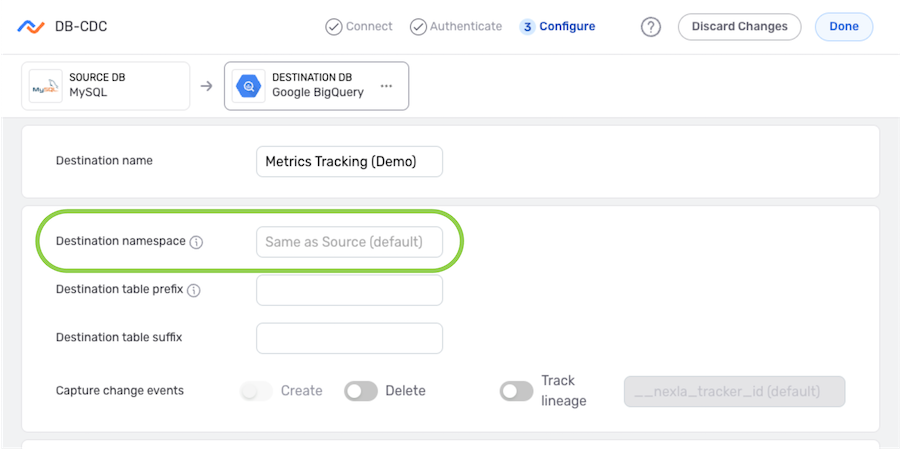
Destination Table
Nexla can be configured to include a prefix and/or suffix in the title of any tables created in the destination of a DB-CDC data flow.
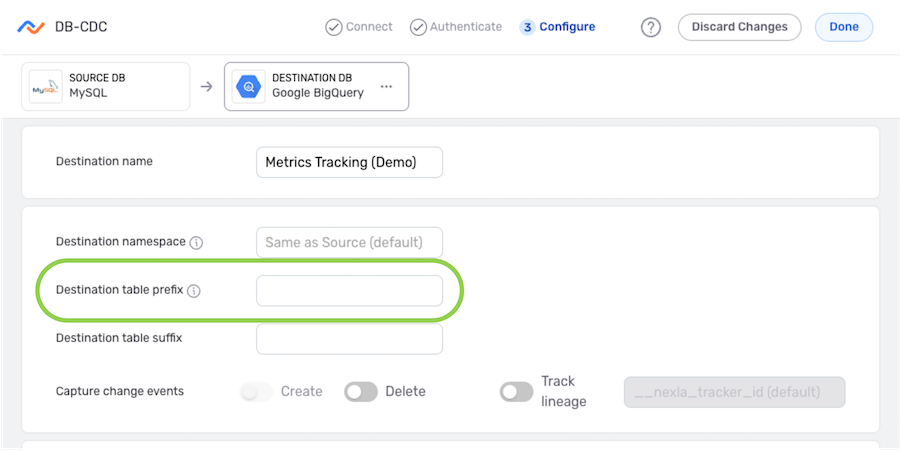
▷ To include a prefix in the title of created tables:
-
Enter the prefix that will be included for each table in the Destination Table Prefix field.
▷ To include a suffix in the title of created tables:
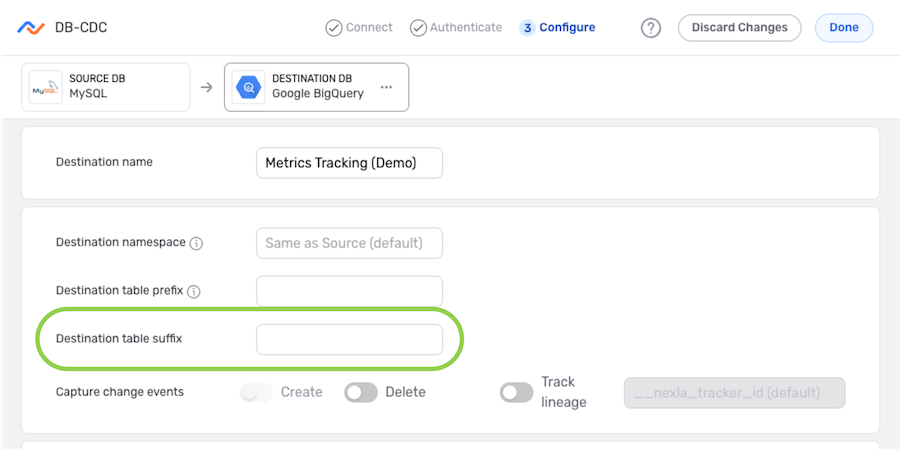
-
Enter the suffix that will be included for each table in the Destination Table Suffix field.
Change Capture Settings
In a DB-CDC data flow, Nexla will always capture data that is newly created in the source location and replicate that data into the destination location. However, users can choose whether or not data deletions in the source location will also be reflected into the destination.
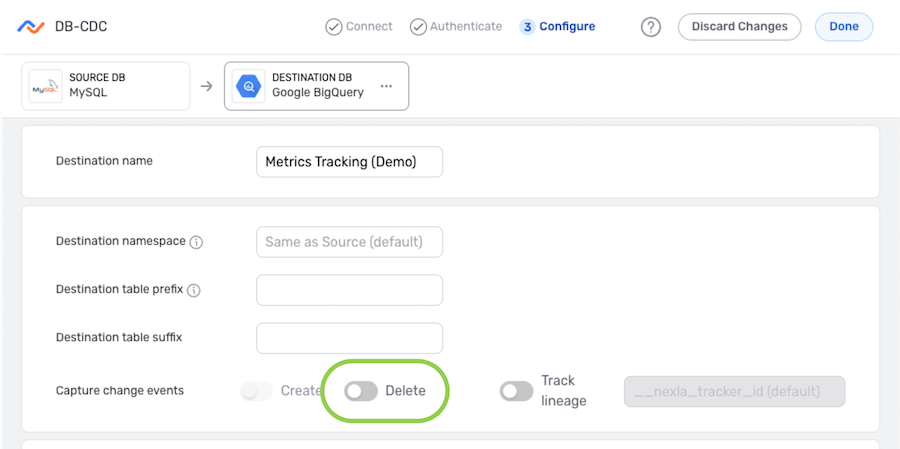
▷ To only reflect newly created data into the destination, without synching any data deletions, in this DB-CDC flow:
-
In the Capture change events settings, ensure that the Delete switch is in the off position (gray). This is the default setting, so typically, no change is needed.
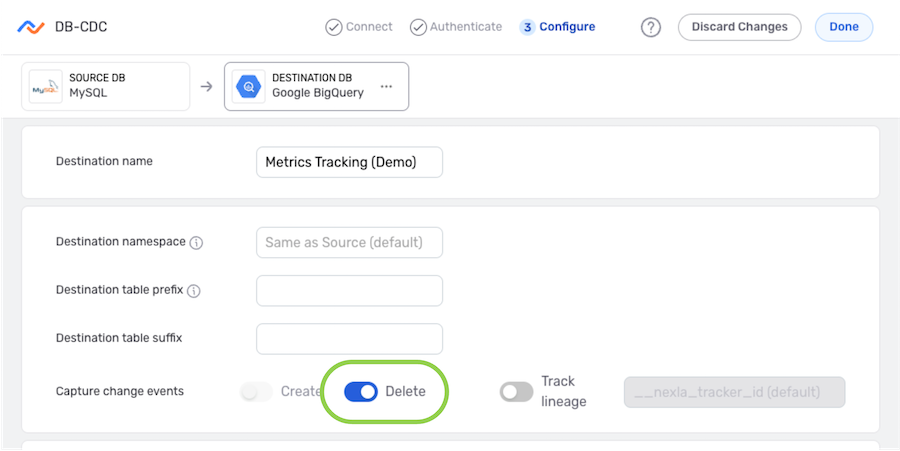
▷ To reflect data deletions in addition to newly created data into the destination in this DB-CDC flow:
-
In the Capture change events settings, activate the Delete setting by clicking on the slide switch. Once activated, the switch will turn blue.
Record Lineage Tracking
Nexla provides the option to trace the lineage of records sent to the destination in DB-CDC data flows. This lineage includes the origin of the record data, all applied transformations or changes, and all destinations to which the record data has been sent over time.
-
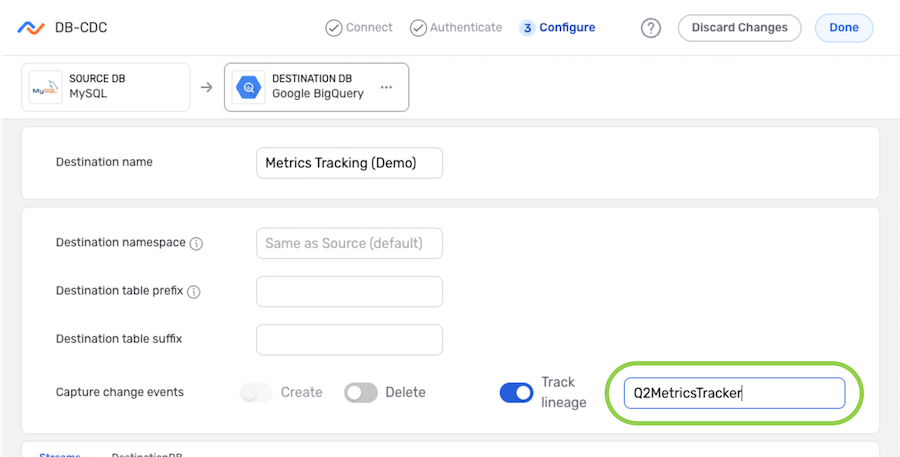
To enable record lineage tracking, click on the Track Lineage slide switch. Once activated, the switch will turn blue.
-
Enter the tracker name in the Track Lineage text field. Nexla will include an attribute with the name entered in this field. This attribute will be assigned a unique value for each record written to the destination.
Stream Selection
Nexla can be configured to replicate all data & changes detected in the data source into the destination location, or users can specify only selected data to be replicated into the destination.
▷ Replicate all detected data & changes into the destination:
-
Under the Streams tab at the bottom of the screen, ensure that the Automatic option is selected. This setting is selected by default, so typically, no change is needed.
Example: All tables in the
nexla_metrics_proddatabase will be replicated
into the DB-CDC flow destination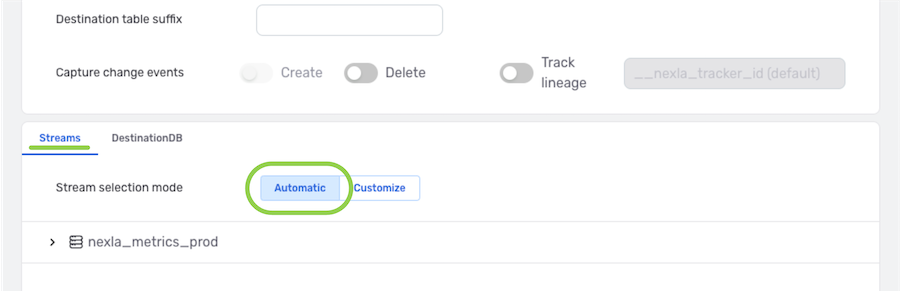
▷ Replicate only data & changes detected in selected locations into the destination:
-
Under the Streams tab at the bottom of the screen, select the Customize option, and deactivate the Sync All slide switch.
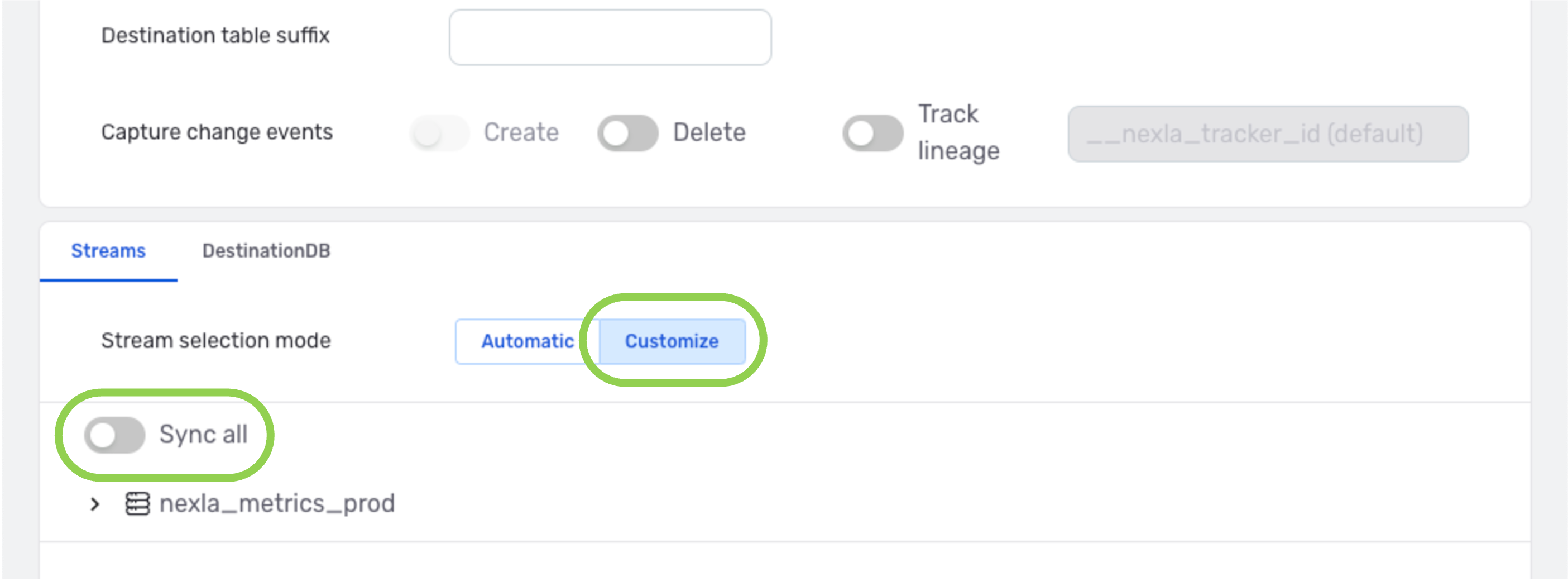
-
Click the
icon next to the database name to expand the list of tables, and check the box(es) next to the table(s) that should be synched to the destination this DB-CDC flow.Example: Only data & detected changes in the
account_metrics_dailyanddata_monitor_dailytables
will be replicated into the DB-CDC flow destination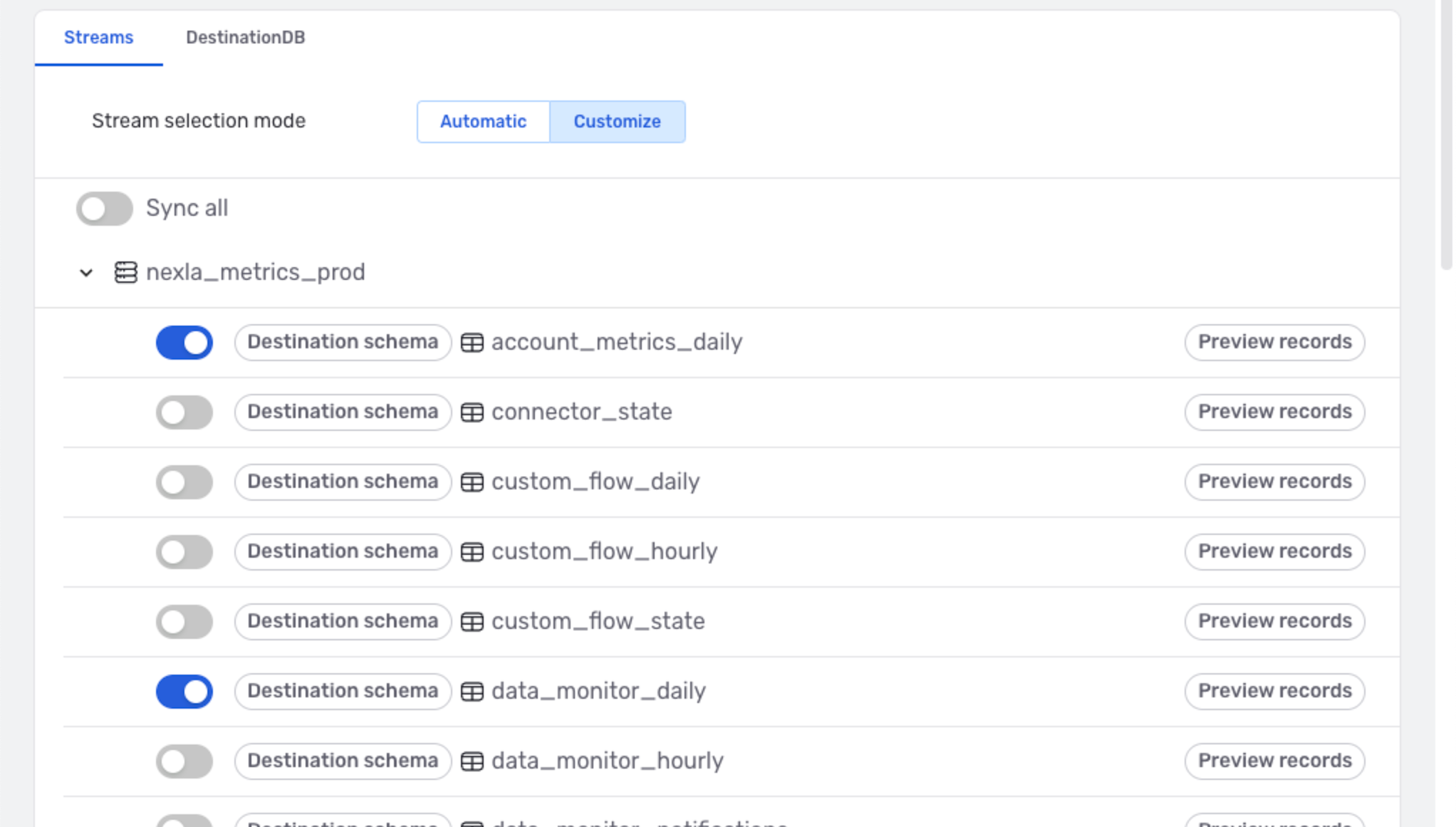
Save & Activate the Destination
-
Once all required settings and any desired additional options are configured, click
in the top right corner of the screen to save the data destination.Important: Data MovementData will not begin to flow into the destination until it is activated by following the instructions below.
- To activate the destination, click the icon on the destination, and select from the dropdown menu.
Spark ETL Data Flows
- Enter a name for the destination in the Name field.
-
Optional: Enter a brief description of the destination in the Description field.
Resource DescriptionsResource descriptions should provide information about the resource purpose, data freshness, etc. that can help the owner and other users efficiently understand and utilize the resource.
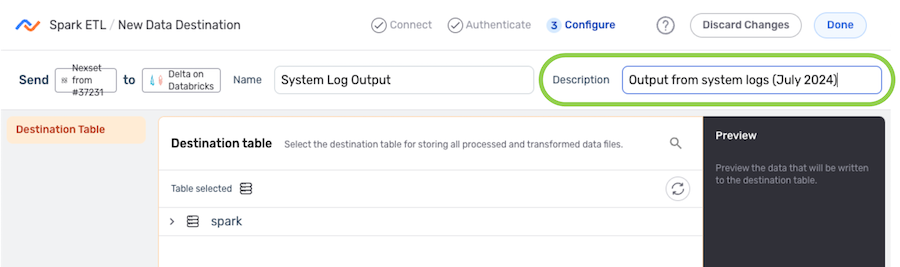
Configure the Destination
Destination Table
-
Under the Destination Table section, navigate to the table to which Nexla will write the Nexset data; then, hover over the listing, and click the
icon to select this location.- To view/select a nested location, click the icon next to a listed folder to expand it.
- To view/select a nested location, click the
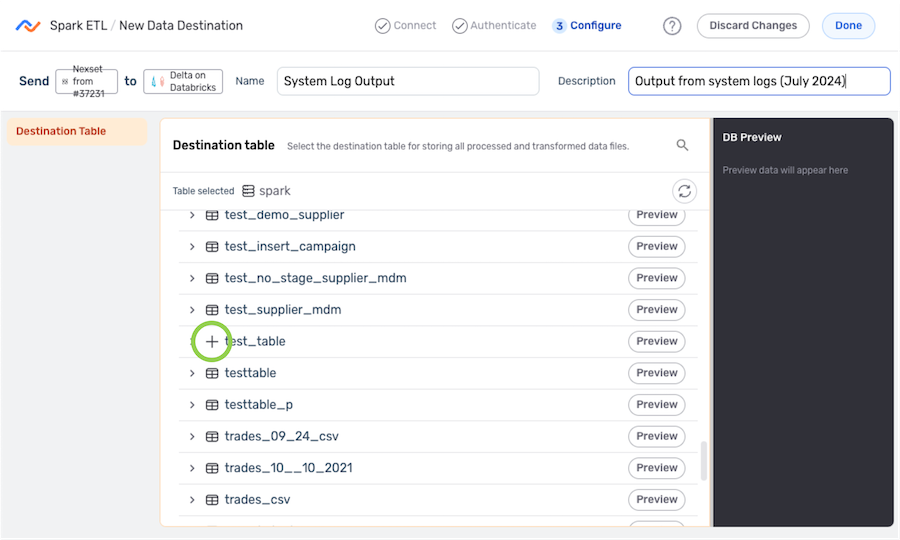
- The selected directory location is displayed at the top of the Destination Table section.
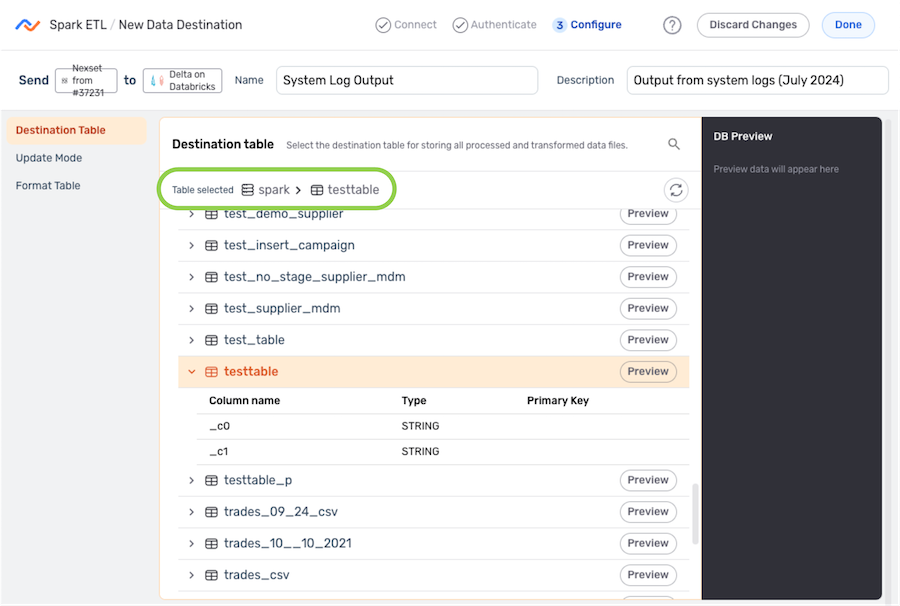
Update Mode
- Under Update Mode, select whether the records contained in the Nexset should be inserted or upserted into the table using the Update Mode pulldown menu.
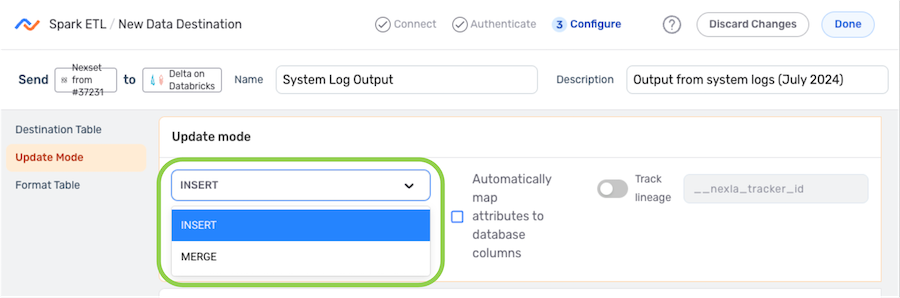
Record Lineage Tracking
Nexla provides the option to trace the lineage of records sent to the destination in Spark ETL data flows. This lineage includes the origin of the record data, all applied transformations or changes, and all destinations to which the record data has been sent over time.
-
To enable record lineage tracking, click on the Track Lineage slide switch under Update Mode. Once activated, the switch will turn blue.
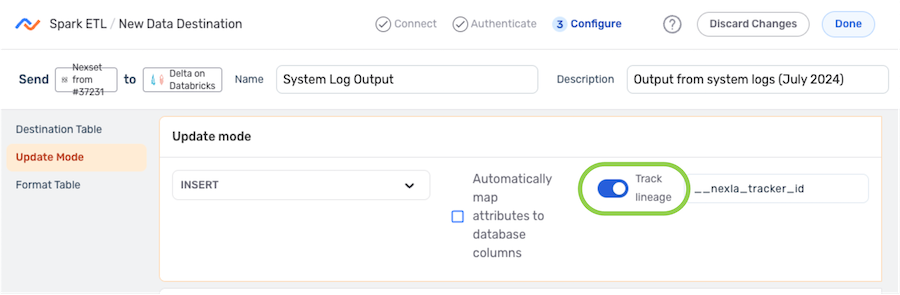
-
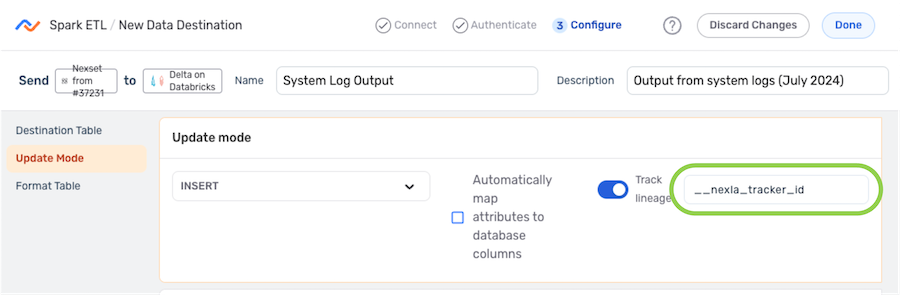
Enter the tracker name in the Track Lineage text field. Nexla will include an attribute with the name entered in this field. This attribute will be assigned a unique value for each record written to the destination.
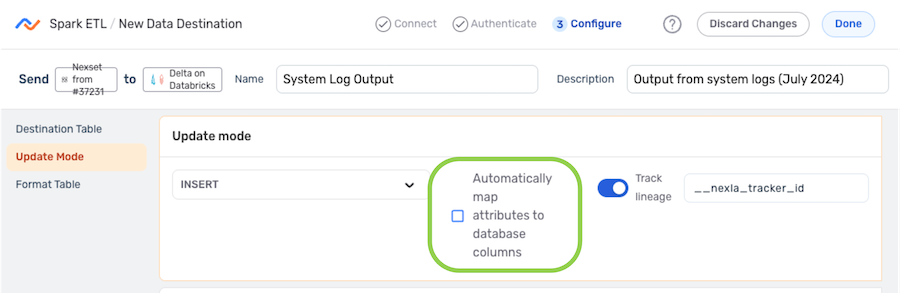
Automatic Mapping
- To configure Nexla to automatically map the Nexset record attributes to columns in the database, check the box next to Automatically map attributes to database columns.
Save & Activate the Destination
-
Once all required settings and any desired additional options are configured, click
in the top right corner of the screen to save the data destination.Important: Data MovementData will not begin to flow into the destination until it is activated by following the instructions below.
- To activate the destination, click the icon on the destination, and select from the dropdown menu.
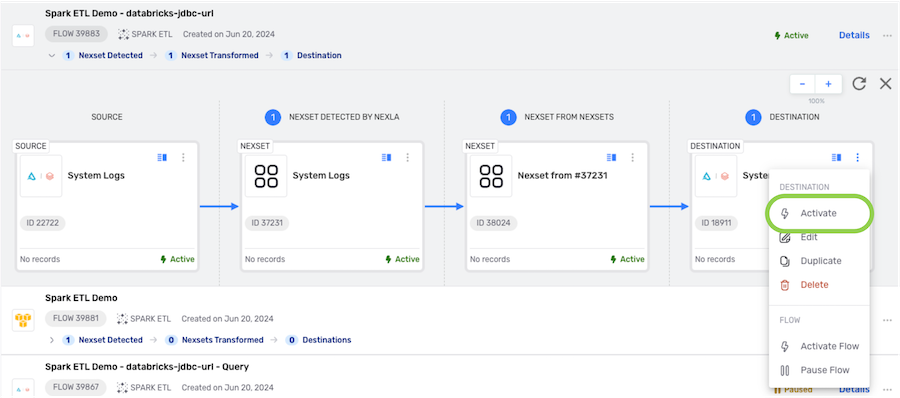
Replication Data Flows
- Enter a name for the destination in the Name field.
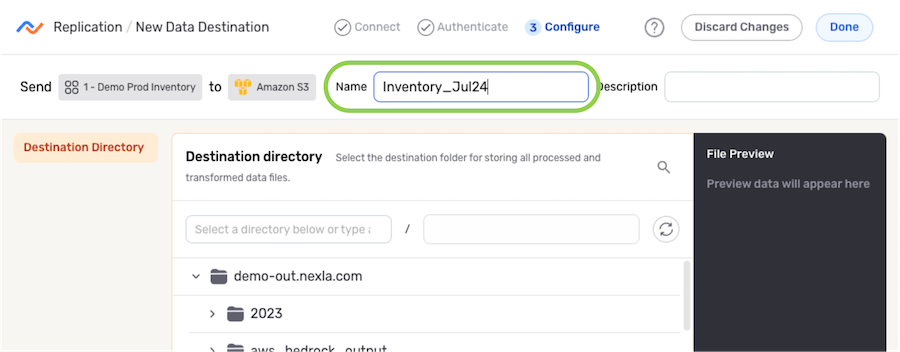
-
Optional: Enter a brief description of the destination in the Description field.
Resource DescriptionsResource descriptions should provide information about the resource purpose, data freshness, etc. that can help the owner and other users efficiently understand and utilize the resource.
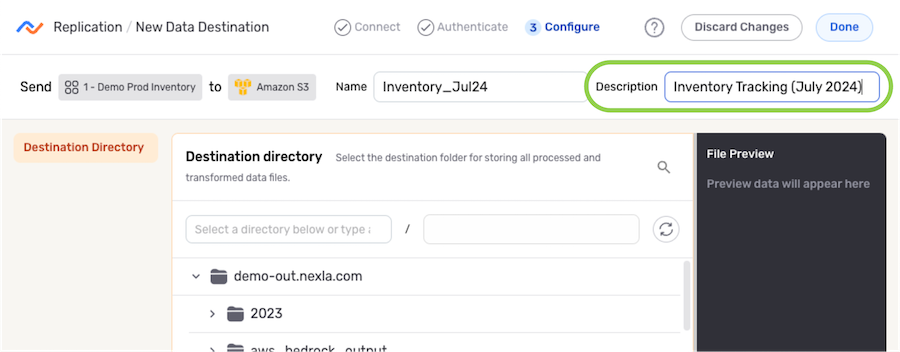
Configure the Destination
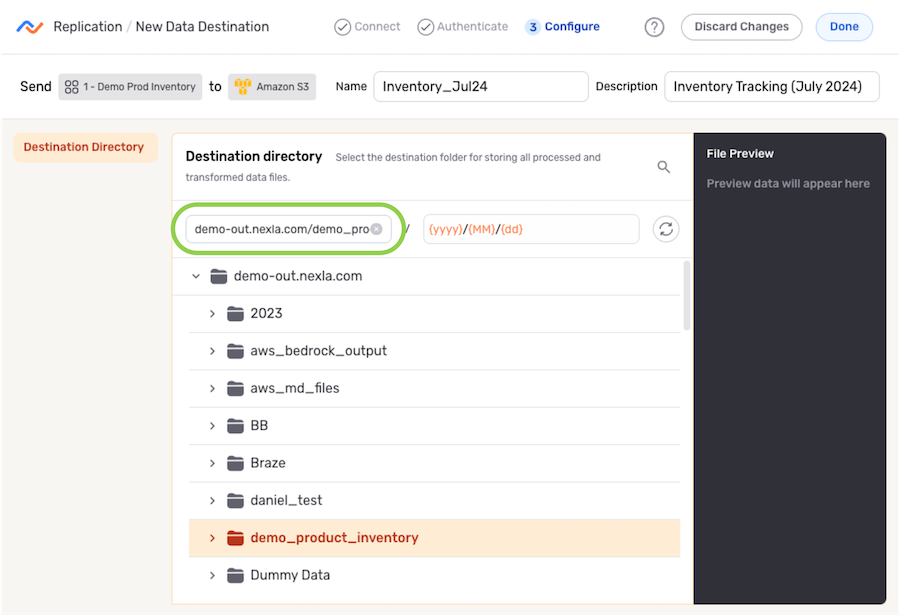
Destination Directory
-
Under the Destination Directory section, navigate to the directory location into which Nexla will replicate the Nexset data; then, hover over the listing, and click the
icon to select this location.- To view/select a nested location, click the icon next to a listed folder to expand it.
- To view/select a nested location, click the
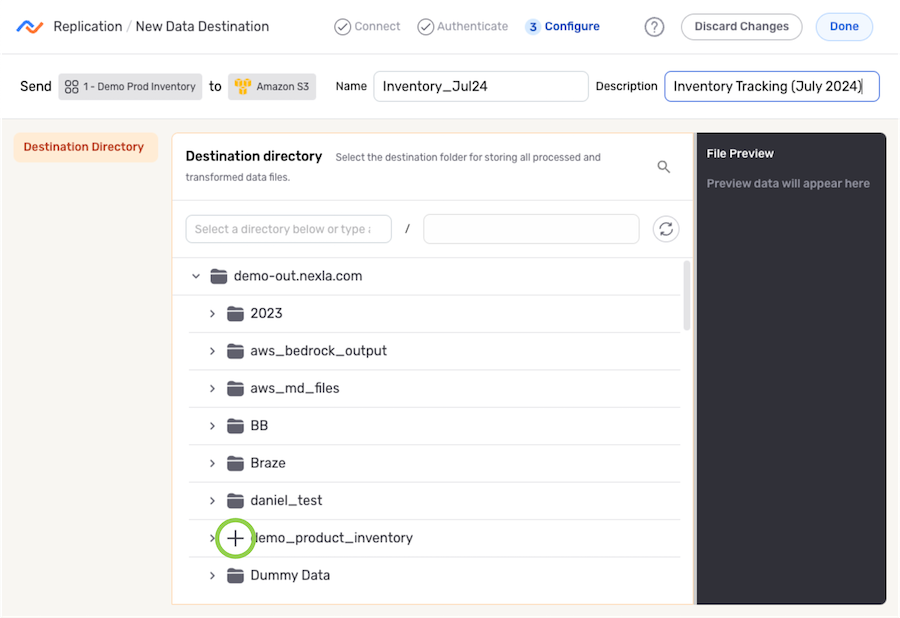
- The selected directory location is displayed at the top of the Destination Directory section.
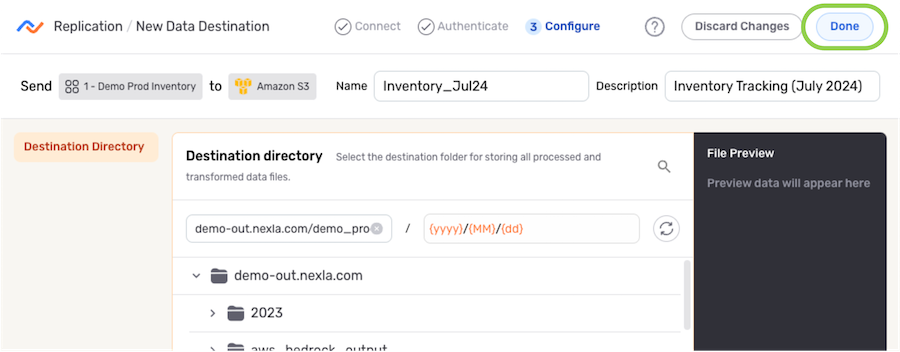
Save & Activate the Destination
-
Once all required settings and any desired additional options are configured, click
in the top right corner of the screen to save the data destination.Important: Data MovementData will not begin to flow into the destination until it is activated by following the instructions below.
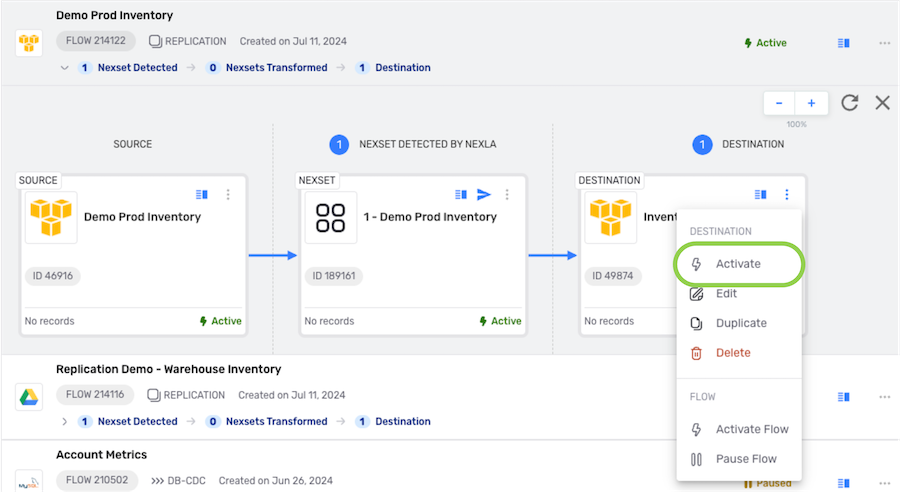
- To activate the destination, click the icon on the destination, and select from the dropdown menu.
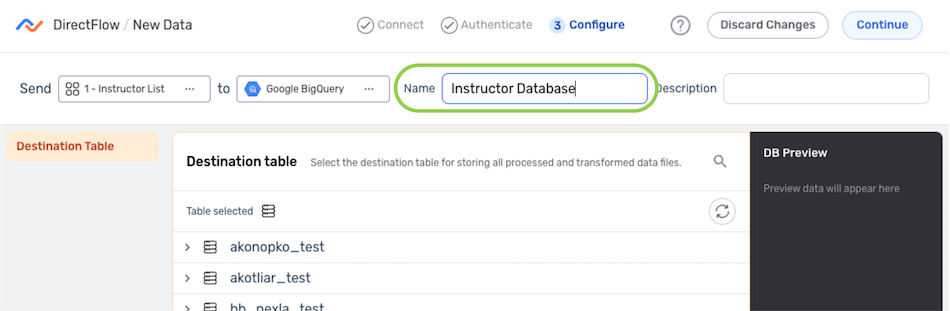
DirectFlow Data Flows
- Enter a name for the destination in the Name field.
-
Optional: Enter a brief description of the destination in the Description field.
Resource DescriptionsResource descriptions should provide information about the resource purpose, data freshness, etc. that can help the owner and other users efficiently understand and utilize the resource.
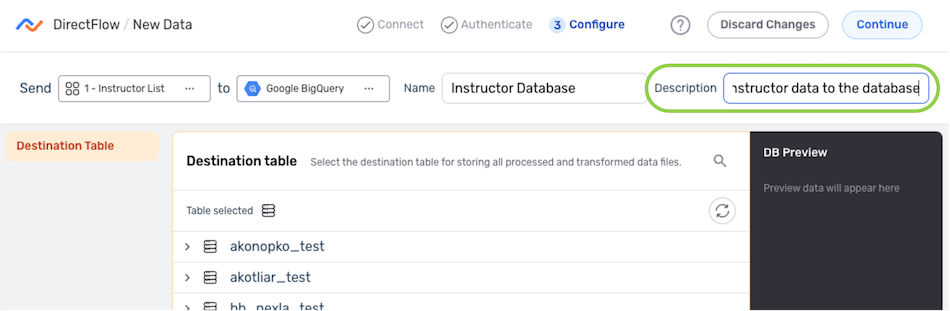
Configure the Destination
Destination Table
-
Under the Destination Table heading, locate the table to which Nexla will send the Nexset data; then, hover over the table listing, and click the
icon to select this location.- To view/select a nested location, click the icon next to a listed folder to expand it.
- To view/select a nested location, click the
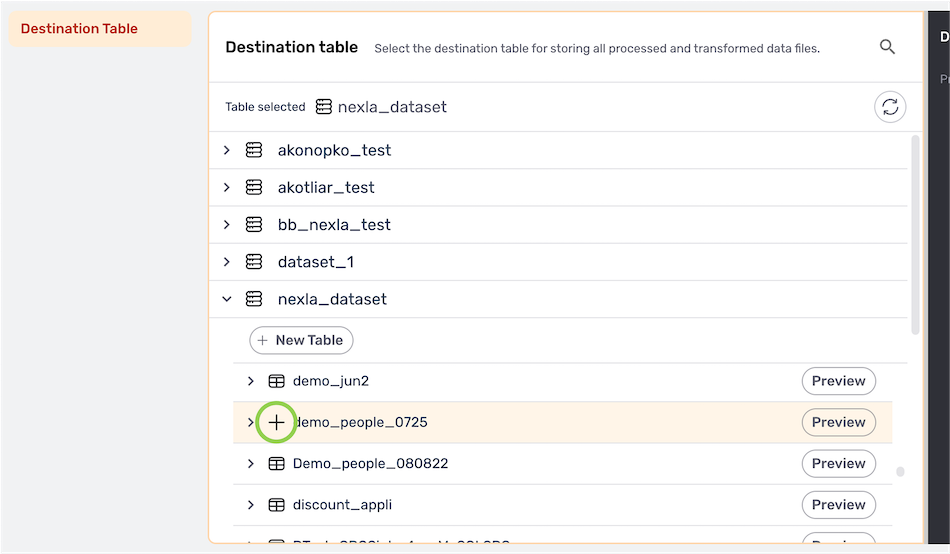
- The selected table location is displayed at the top of the directory list.
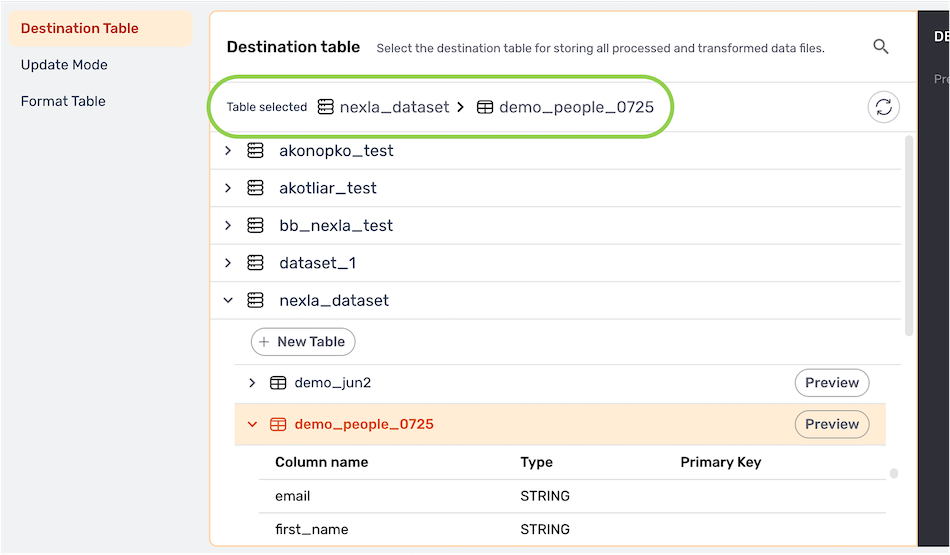
Update Mode
Nexla can be configured to insert or upsert the Nexset data into the database table.
-
Insert – When this update mode is selected, the Nexset record attributes will be inserted into the destination table as new columns.
-
Upsert – When this update mode is selected, the values in each Nexset record attribute corresponding to an existing column in the destination table will be used to update that column, and any record attributes that do not correspond to an existing column will be inserted as new columns.
▷ To use the Insert update mode:
- Under the Update Mode settings category, select Insert from the pulldown menu.
- When using Insert mode, Nexla can be configured to automatically map the Nexset attributes to existing columns in the destination table. To use this option, check the box next to Automatically map attributes to database columns; or, to manually map the Nexset attributes to table columns, uncheck this box to disable automatic mapping.
-
When automatic column mapping is enabled, the schema of the selected destination table is shown under the Format Table settings category. Linked attributes, column names, and data types cannot be changed as described in the Column Mapping section below; instead, edit or transform the Nexset to make any needed changes.
- Continue to the Column Mapping settings.
▷ To use the Upsert update mode:
- Under the Update Mode settings category, select Upsert from the pulldown menu.
- By default, Nexla is configured to allow destination table columns to be updated with null values when using Upsert mode. To omit null Nexset record attribute values from the upsert and allow the Nexset records to be partially upserted, disable this option by unchecking the box next to Allow column updates with nulls.
- Under the Format Table settings category, select the attribute that will be used as the primary key by checking the box under Primary to the right of that attribute.
- Continue to the Column Mapping settings.
Column Mapping
The Nexset attributes are mapped to columns in the destination table under the Format Table settings category.
▷ Existing Table:
When sending data to an existing table, Nexla will automatically provide a draft column map with Nexset attributes linked to matching destination table columns. Linked draft attributes can be changed and/or selected using the pulldown menus.
▷ New Table:
When the destination is a new table, the draft column map will be populated with suggested column names and data types. Suggested column names can be edited directly in the field, and data types can be changed using the pulldown menu.
Save & Activate the Destination
- After configuring all necessary settings, click in the upper right corner of the screen to save and create the destination.
Important: Data Movement
Data will not begin to flow into the destination until it is activated, as shown in the following step.
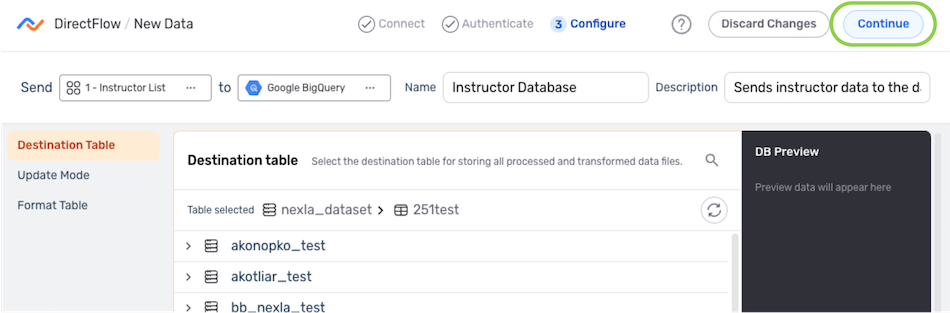
- Once created, the destination must be activated to begin the flow of data into the destination. To activate the destination, click the icon on the destination, and select from the dropdown menu.
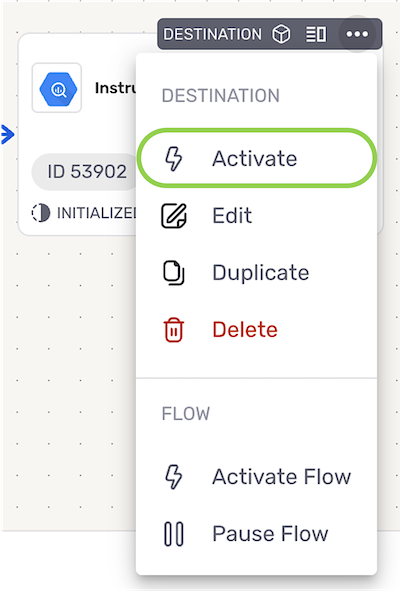
ELT Data Flows
Configure the Destination
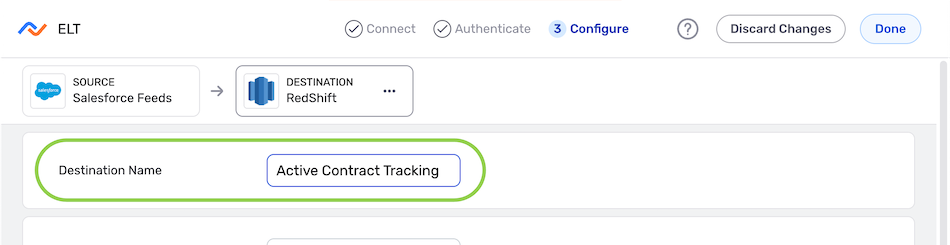
- Enter a name for the destination in the Destination Name field.
- Enter the name of the database in which the table(s) containing the Nexset data will be created in the Database Name field.
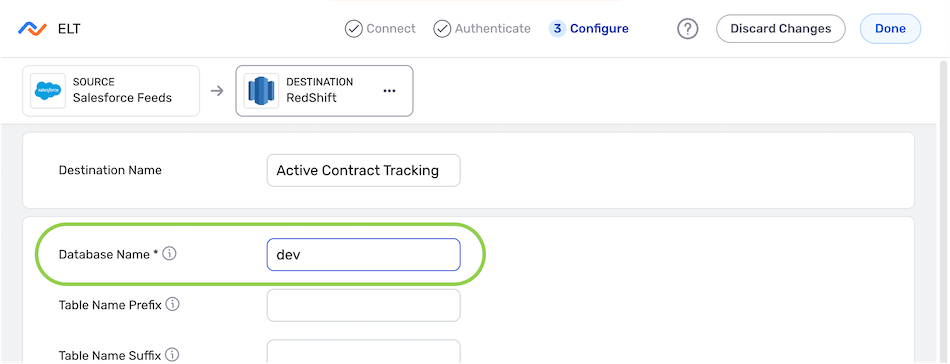
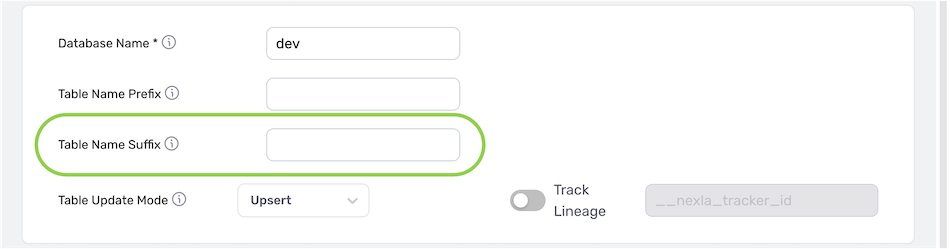
Table Name Prefix/Suffix
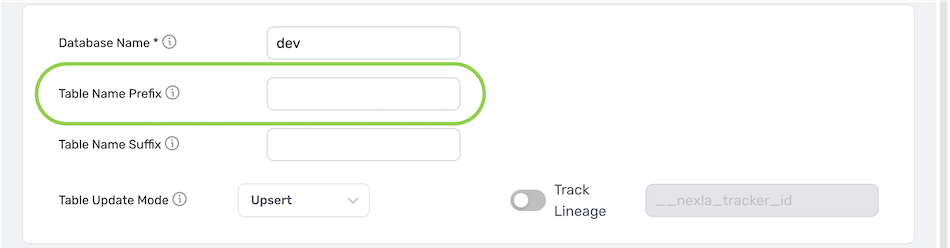
- Optional: If a prefix should be applied to the names of tables created within the destination database/data warehouse, enter the desired prefix text in the Table Name Prefix field.
- Optional: If a suffix should be applied to the names of tables created within the destination database/data warehouse, enter the desire suffix text in the Table Name Suffix field.
Record Lineage Tracking
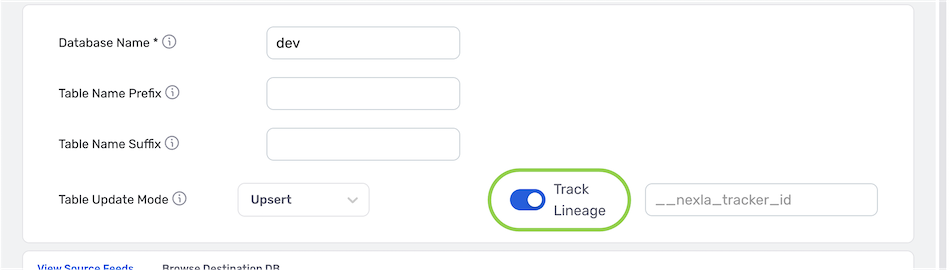
Nexla provides the option to trace the lineage of records sent to the database table. This lineage includes the origin of the record data, all applied transformations or changes, and all destinations to which the record data has been sent over time.
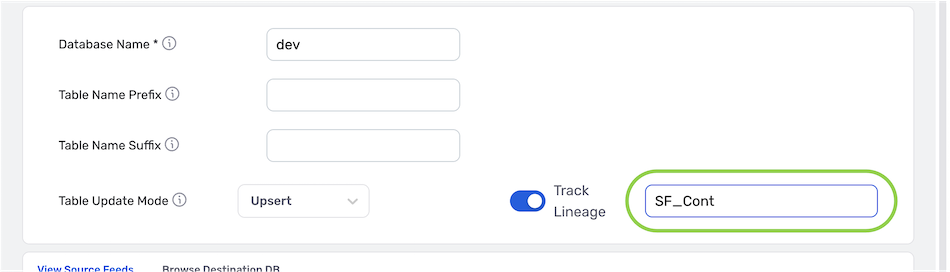
- To enable record lineage tracking, click on the Track Lineage slide switch. Once activated, the switch will turn blue.
- Enter the tracker name in the Track Lineage text field. Nexla will include an attribute with the name entered in this field. This attribute will be assigned a unique value for each record written to the destination.
Save & Activate the Destination
- After configuring all necessary settings, click in the upper right corner of the screen to save and create the destination.
Important: Data Movement
Data will not begin to flow into the destination until it is activated, as shown in the following step.
- Once created, the destination must be activated to begin the flow of data into the destination. To activate the destination, click the icon on the destination, and select from the dropdown menu.