RAG Data Flows
RAG data flows provide a simplified way for organizations to harness the information synthesis power of GenAI & LLMs to intelligently query their data—from inventory & customer review data to sensitive/protected datasets and much more—with rapidly generated responses presented in natural, easy-to-understand language. These flows can be used to power user- and customer-facing applications such as chatbots, providing an easy interactive experience in which user questions are answered quickly and accurately.
RAG Flows
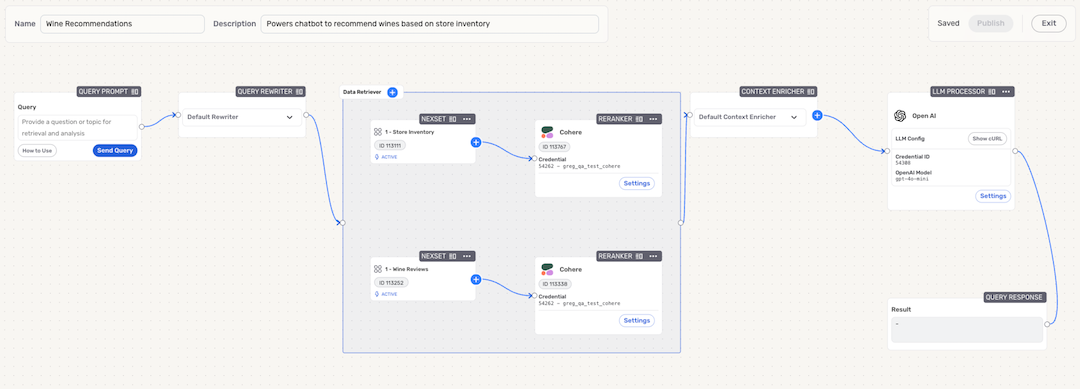
In a RAG flow, Nexla users designate which information will be used to answer submitted queries—this information can be sourced from a variety of locations, including APIs, vector databases, existing Nexsets, etc. When a query is submitted to the RAG flow, the data retriever determines what information is needed to answer the query and retrieves relevant data from the selected source(s), and a reranker refines the retrieved data to ensure that only the most relevant data is passed to the configured LLM. Then, the LLM analyzes the data that it receives and generates a response to the query. When a RAG flow is integrated into an external application, the generated response is then shown to the application user.
When creating a RAG flow in Nexla, users can add multiple data sources to the data retriever,as well as configure multiple LLMs to generate responses. This allows for the creation of complex RAG flows that can handle a wide variety of queries and provide detailed, accurate responses.
Example RAG Flow
Create a RAG Flow
Follow the steps below to create a new RAG data flow in Nexla and to learn more about each element of RAG flows.
- After logging into Nexla, navigate to the Integrate section, and click the New Data Flow button at the top of the toolbar on the left.
- Select RAG Flow from the list of flow types, and click Create to begin building a new RAG data flow.
1. Reference Data
In the Data Retriever node, one or more sources of data can be selected for reference in the RAG flow. From this node, users can select existing Nexsets or create a new data retriever to provide data for reference in the RAG flow.
Nexsets and data sources used in the RAG flow data retriever must be data feed API-compatible. Additionally, ensure that any variables that may need to be substituted in API calls made in response to queries are explicitly defined in the data source configuration. This will allow the RAG flow to retrieve additional data needed to answer submitted queries.
▷ Select an existing Nexset:
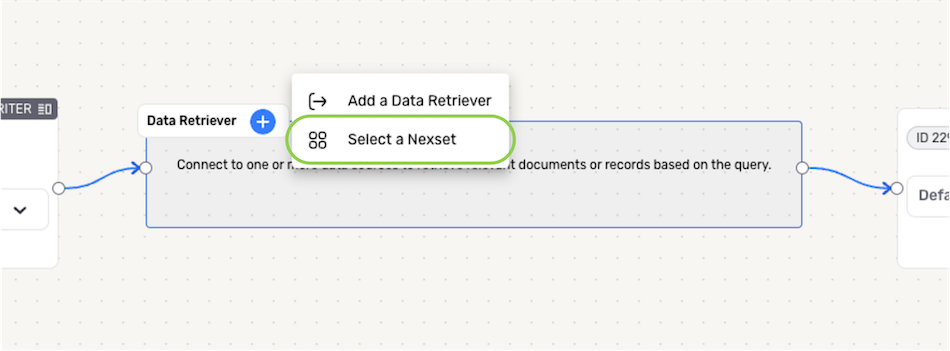
- Click the + icon on the Data Retriever, and select the Select a Nexset option from the menu.
-
Check the box next to the Nexset(s) containing data that will be referenced in this RAG flow; then, click the Choose button in the bottom right corner of the panel to add the Nexset(s) to the Data Retriever.
RAG Flow Nexset SelectionOnly Nexsets that meet the data feed API compatibility requirements for RAG flows are shown in the Nexset selection panel.
Nexset Selection
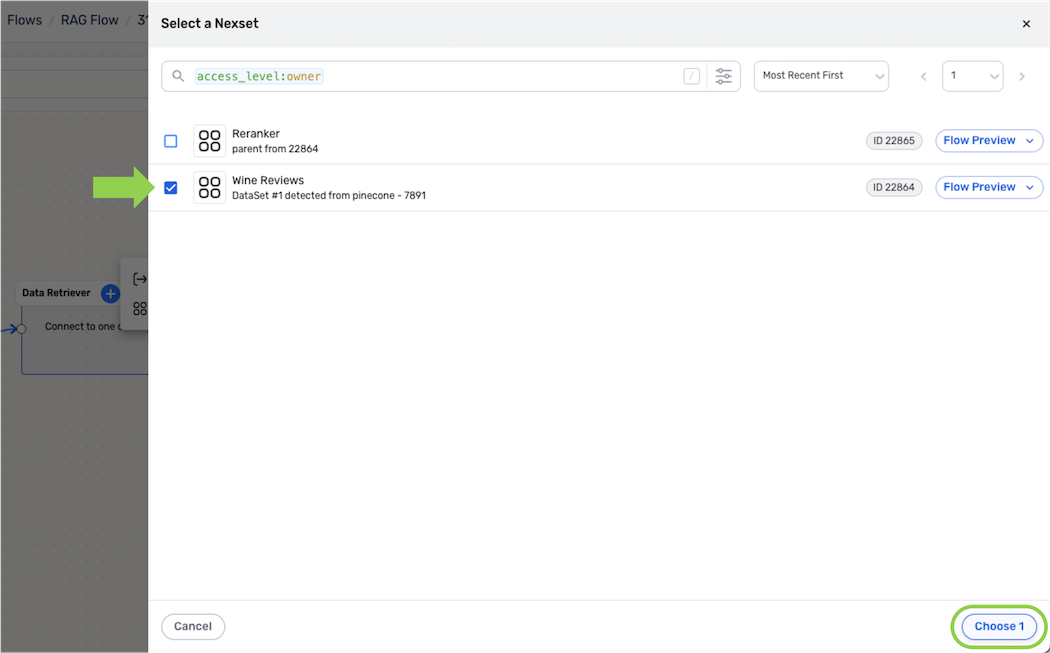
Nexset Added to Data Retriever
▷ Add a new data retriever:
When a new data retriever is added in the RAG flow wizard, a data source will be created within a new FlexFlow data flow, and data in the configured location will be retrieved and referenced when queries are submitted. This FlexFlow can also be viewed in the All Data Flows screen and includes the same editing and control options available for other FlexFlows.
- Click the + icon on the Data Retriever, and select the Add a Data Retriever option from the menu.
-
In the FlexFlow creation overlay, select the connector type for the data retriever; then, select the credential that will be used to authenticate to the source location, and click Next.
RAG Data Retriever SourcesOnly connectors that meet the data feed API compatibility requirements for RAG flows are available for selection when creating a new data retriever.
-
Configure the data source settings, including the source name & description, location/endpoint from which data will be retrieved, and other connector-specific settings, following the same process used to create a new source in a standard FlexFlow.
-
For sources such as vector databases, explicitly define any variables that may be substituted in API calls made in the RAG flow—for example, in the dense vector field, enter
{vector=[0.1,0.5,0.8...]}rather than the vector value alone. -
More information on configuring data sources can be found in the guides available in the Connectors section.
-
-
Once the source is configured, click Create in the top right corner of the overlay to save the data source and add it to the Data Retriever node in the RAG flow.
New Data Retriever Added
2. Reranker (Vector Database Sources)
A reranker is only required for vector database sources. For other source types, skip this section, and proceed to the LLM processor section.
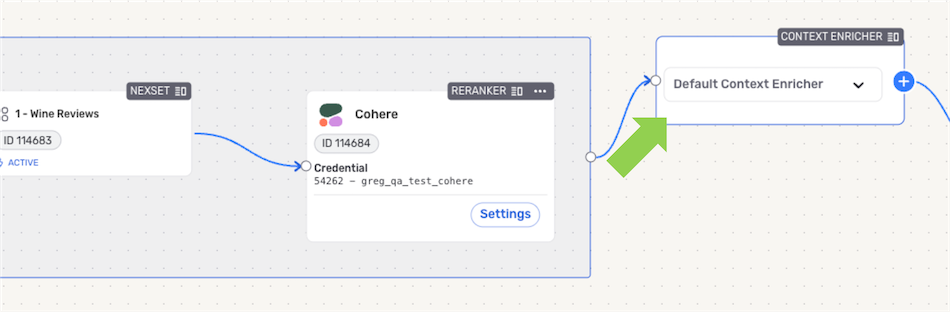
For vector database sources added to the Data Retriever, a reranker should be added. With each query submitted to the RAG flow, the reranker will refine the retrieved data before passing it to the LLM, ensuring that only the most relevant data is passed.
- To add a reranker to a vector database source in the Data Retriever, click the + icon on the Nexset detected from the source, and select Add Reranker.
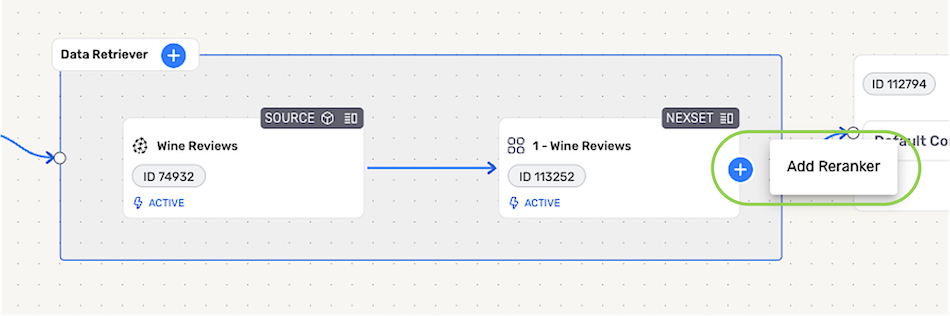
-
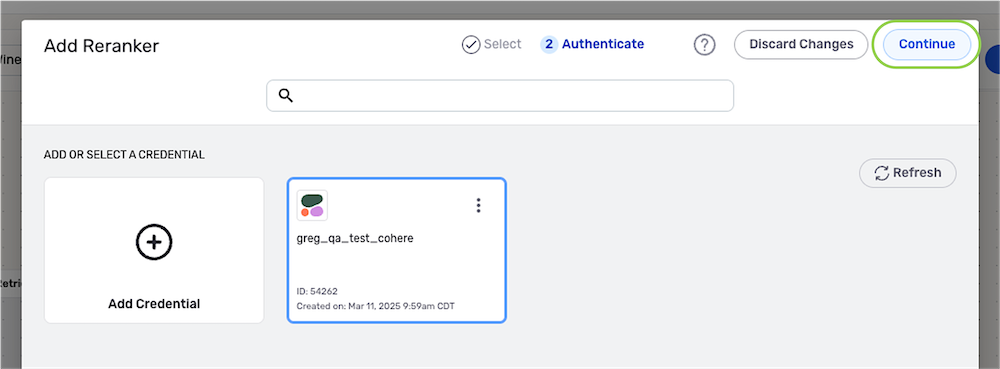
In the Add Reranker overlay, select the Cohere connector; then, select or create the Cohere credential that will be used with this flow, and click Continue to add the reranker to the source.
Add Reranker Overlay
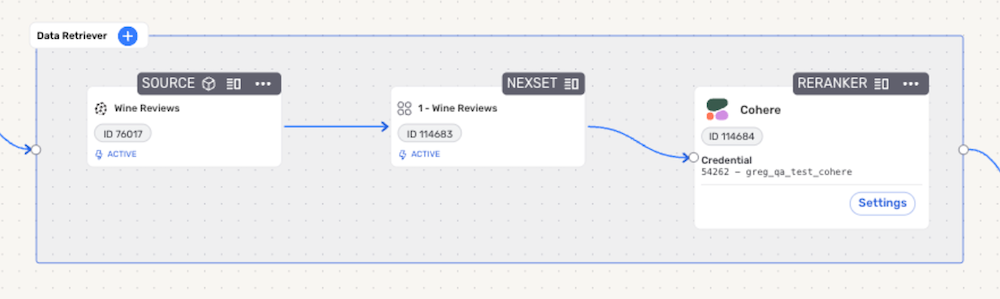
Reranker Node Added to the Data Retriever
3. Query Rewriter
In a RAG flow, the Query Rewriter analyzes the query submitted by the user and rewrites it to ensure that the query can be correctly interpreted by the data retriever and LLM processor. The query rewriter can also be used add context to a submitted query, such as by providing acronym definitions or specifying types of data that should or should not be included in the query responses.
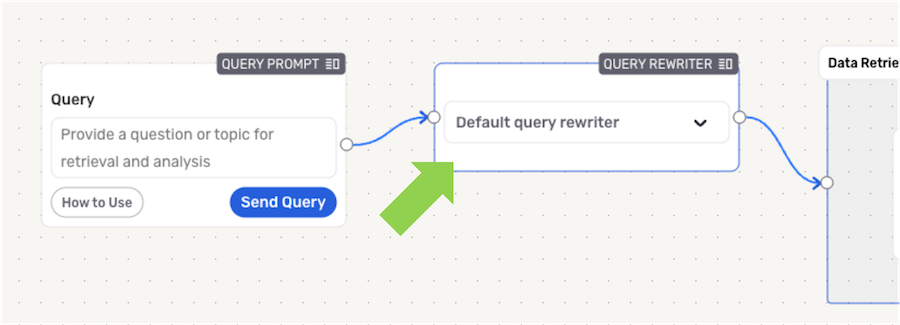
▷ Default Query Rewriter:
Nexla provides a default query rewriter that is automatically selected when a new RAG flow is created. This default query rewriter is a generic rewriter that can be used to rewrite queries for most use cases, and it can be used without any additional configuration.
▷ Enriched Query Rewriter:
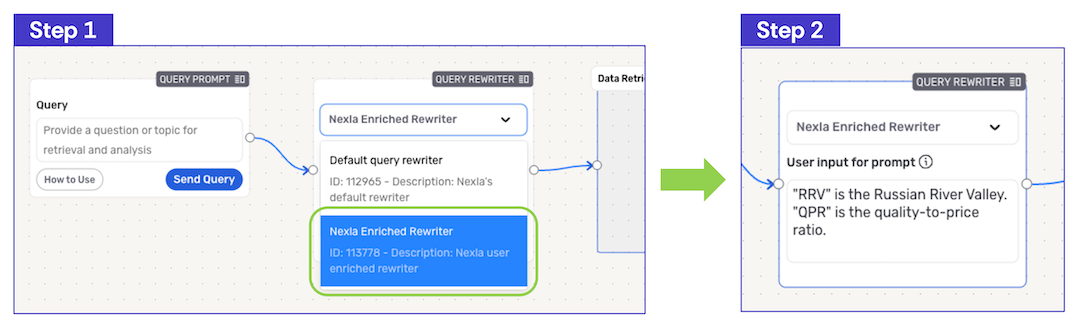
To provide more advanced query rewriting capabilities, a custom enriched query rewriter can be configured by providing context and other information to the rewriter using natural language, without requiring any code. An enriched query rewriter can be tailored to suit the intended use of the RAG flow—for example, it can expand industry-specific acronyms that users may include in their queries, or it can specify types of data that should not be retrieved or included in the query response.
- To use the enriched query rewriter in this RAG flow, select Nexla Enriched Rewriter from the pulldown menu in the Query Rewriter node, and enter the relevant information that will help the rewriter analyze and rewrite queries in the provided text field using natural language.
4. Context Enricher
The Context Enricher node adds supplementary contextual information to the query and data before passing it to the LLM processor. For example, the context information can inform the LLM about which source includes the freshest or most complete data, define industry-specific acronyms or terms that may be included in retrieved data, or identify sources that provide the most relevant data for answering common query types.
▷ Default Context Enricher:
Nexla provides a default context enricher that is automatically selected when a new RAG flow is created. This default context enricher is a generic enricher that automatically provides context information, such as the data freshness or additional information obtained from a vector database source. No additional configuration is required to use the default context enricher.
▷ Enriched Context Enricher:
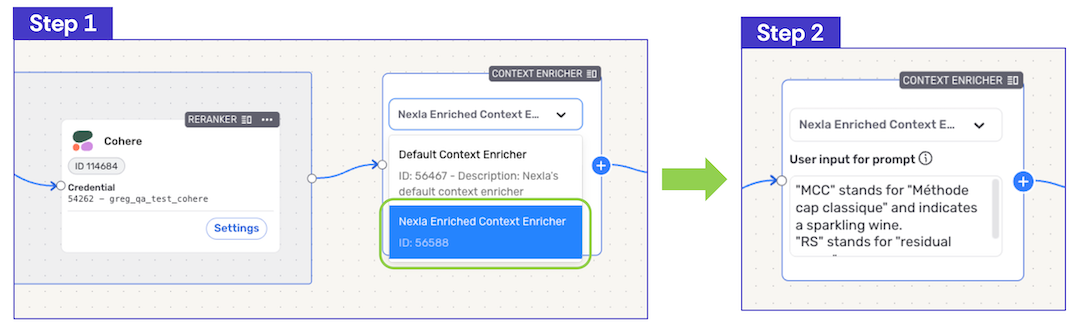
To provide more advanced context enrichment capabilities, a custom enriched context enricher can be configured to provide relevant information tailored to this RAG flow and/or its intended use. Context information is provided using natural language, without requiring any code. This user-provided information could include, for example, definitions of industry-specific acronyms that may be encountered in the retrieved data.
- To use the enriched context enricher in this RAG flow, select Nexla Enriched Context Enricher from the pulldown menu in the Context Enricher node, and enter the relevant information that should be passed to the LLM processor in the provided text field using natural language.
5. LLM Processor
When a query is submitted to the RAG flow, the data retriever will pass relevant data to an LLM processor, which will then analyze the data and generate a response to the query. The generated response will be presented to the end-user of applications that utilize the RAG flow.
Multiple LLM processors can be added to a RAG flow, allowing query responses to be generated by different models.
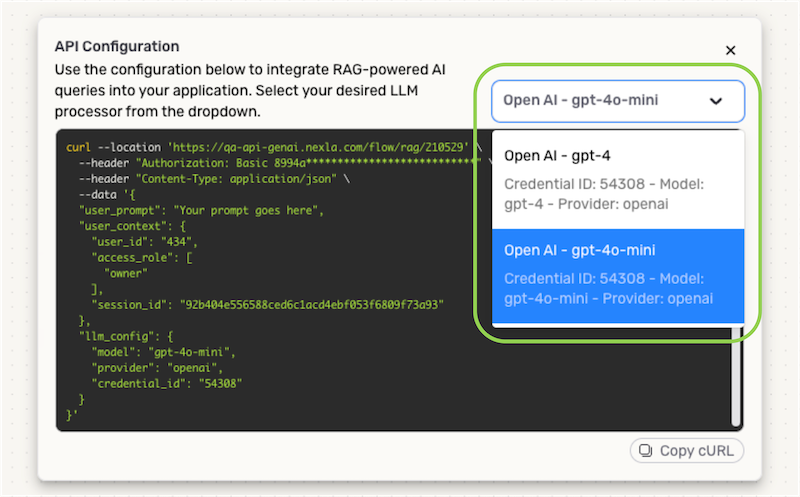
An API configuration cURL is provided for each LLM processor in a RAG flow. When the cURL is incorporated into an external application, only the query response generated by the corresponding model will be provided to the application. More information about integrating RAG flows into external applications is provided in the Application Integration via API section.
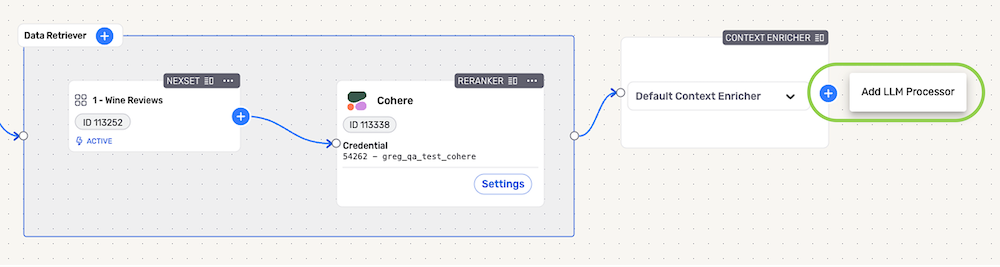
- To add an LLM processor to the RAG flow, click the + icon on the Context Enricher node, and select Add LLM Processor.
-
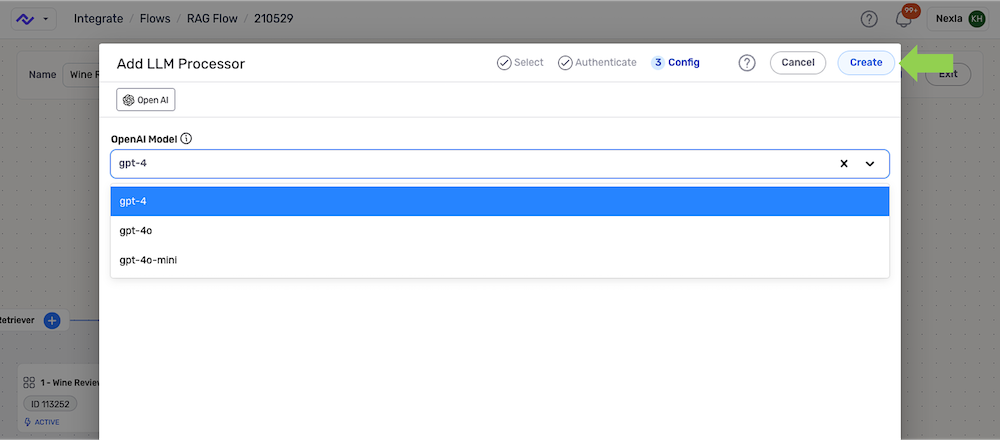
In the Add LLM Processor overlay, select the connector for the LLM provider; then, select or create the credential that will be used to authenticate to the LLM provider, and click Continue.
-
Use the pulldown menu to select the LLM model that will be used to analyze data and provide query responses, and click the Create button to add the LLM processor to the flow.
4. Test & Publish
After all elements of the RAG flow have been added and configured, the flow can be tested within the editor to ensure that query responses are generated as expected. Once the query response(s) are verified, the flow is ready for publication and use in applications.
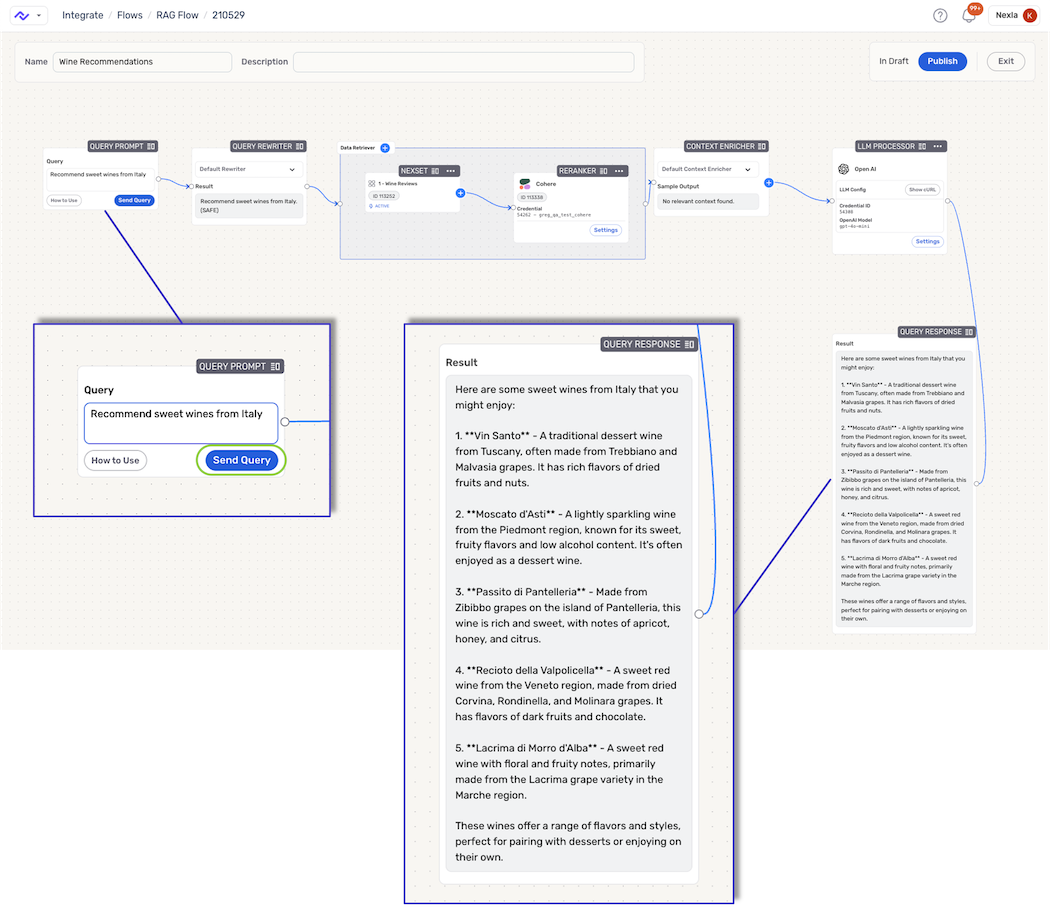
Query Response Testing
To submit a test query, enter the query in the text field of the Query Prompt node, and click the Send Query button.
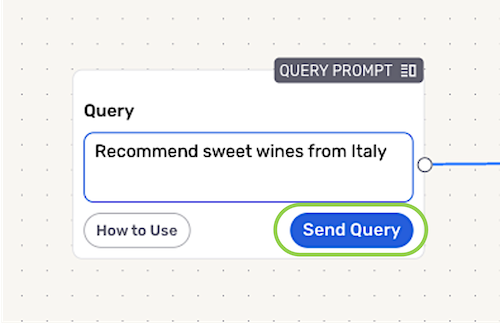
Within the RAG flow, the query will first be analyzed by the query rewriter, and the data retriever will retrieve relevant data from the selected sources. The retrieved data will be refined by the reranker, and relevant data and context information will be passed to the LLM processor, which will analyze the data and generate a response displayed in the Query Response node. Query responses are the content that will be shown to end-users of the application that uses the RAG flow.
Submitting a Test Query
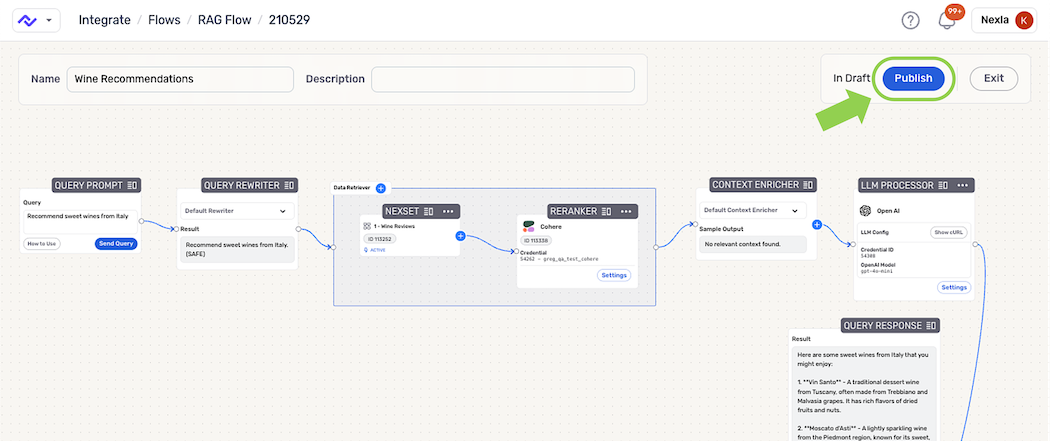
Publish & Save the RAG Flow
When the RAG flow is ready to save, click the Publish button in the top right corner of the editor; then, click Publish in the confirmation dialog to save & publish the flow. This RAG flow is now ready for use both within the Nexla UI and in external applications.
Application Integration via API
Nexla provides the complete API configuration cURL for each LLM processor in a RAG flow, allowing easy integration of the intelligent data-querying functionality of RAG flows into external applications. This allows organizations to create intelligent, real-time data-querying applications tailored to specific needs—including specifying the exact data referenced and the LLM used to generate responses—without the need for complex development work.
- The API configuration cURL for any completed RAG flow can be accessed both from the expanded flow view in the All Data Flows screen and inside the RAG flow editor by clicking the Show cURL button on an LLM processor node in the flow.
- The complete cURL needed to integrate RAG-powered querying using the LLM configured in this node is displayed in the API Configuration window. Simply copy the cURL and insert it into the external application's code.
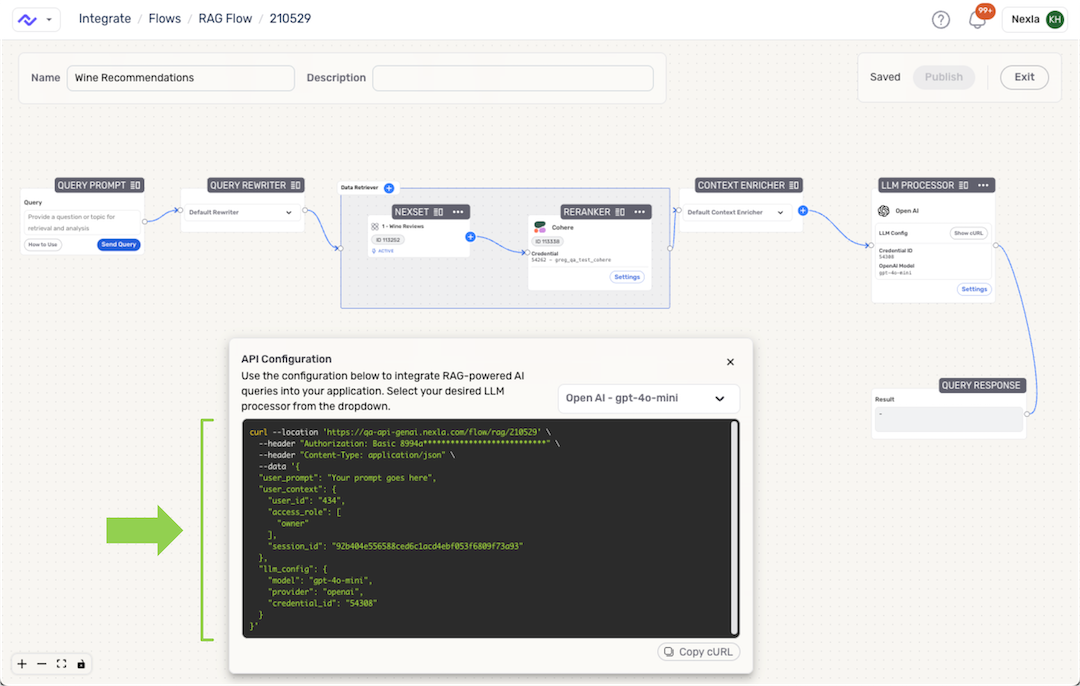
- If more than one LLM is included in the RAG flow, the pulldown menu in the API Configuration window can be used to access the cURL corresponding to any available model.