Adobe Experience Platform Data Source
Adobe Experience Platform
Create a New Data Flow
-
To create a new data flow, navigate to the Integrate section, and click the New Data Flow button. Then, select the desired flow type from the list, and click the Create button.
-
Select the Adobe Experience Platform connector tile from the list of available connectors. Then, select the credential that will be used to connect to the Adobe Experience Platform instance, and click Next; or, create a new Adobe Experience Platform credential for use in this flow.
-
In Nexla, Adobe Experience Platform data sources can be created using pre-built endpoint templates, which expedite source setup for common Adobe Experience Platform endpoints.
Configure Using a Template
Nexla provides pre-built templates that can be used to rapidly configure data sources to ingest data from common Adobe Experience Platform endpoints. Each template is designed specifically for the corresponding Adobe Experience Platform endpoint, making data source setup easy and efficient.
Endpoint Settings
-
Select the endpoint from which this source will fetch data from the Endpoint pulldown menu. Available endpoint templates are listed in the expandable boxes below. Click on an endpoint to see more information about it and how to configure your data source for this endpoint.
Endpoint Testing
Once the selected endpoint template has been configured, Nexla can retrieve a sample of the data that will be fetched according to the current settings. This allows users to verify that the source is configured correctly before saving.
-
To test the current endpoint configuration, click the Test button to the right of the endpoint selection menu. Sample data will be fetched & displayed in the Endpoint Test Result panel on the right.
-
If the sample data is not as expected, review the selected endpoint and associated settings, and make any necessary adjustments. Then, click the Test button again, and check the sample data to ensure that the correct information is displayed.
Configure Manually
Adobe Experience Platform sources can be manually configured to ingest data from any valid Adobe Experience Platform API endpoint.
API Endpoint URL
-
Enter the URL of the Adobe Experience Platform API endpoint from which this source will fetch data in the Set API URL field. This should be the complete URL including the protocol (
https://) and any required path parameters.Adobe Experience Platform exposes several base URLs depending on the service being accessed. Common base URLs include:
- Platform API (general):
https://platform.adobe.io - Catalog Service (datasets, batches):
https://platform.adobe.io/data/foundation/catalog - Real-Time Customer Profile:
https://platform.adobe.io/data/core/ups - Segmentation Service:
https://platform.adobe.io/data/core/ups/segment/definitions - Schema Registry:
https://platform.adobe.io/data/foundation/schemaregistry - Query Service:
https://platform.adobe.io/data/foundation/query
For example, to retrieve a list of datasets in your sandbox, the full endpoint URL would be:
https://platform.adobe.io/data/foundation/catalog/dataSetsAll Adobe Experience Platform API requests require sandbox scoping via request headers. Nexla automatically includes your sandbox name from the credential configuration as the
x-sandbox-nameheader, so you do not need to include it manually in the URL. - Platform API (general):
Date/Time Macros (API URL)
Optionally, the API URL can be customized using macros — all macros added to the API URL will be converted into values when Nexla executes the API call. Macros are dynamic placeholders that allow you to create flexible API endpoints that can adapt to different time periods or data requirements.
Macros are particularly useful for Adobe Experience Platform APIs that accept date range parameters, such as filtering datasets or batches by creation or modification date.
-
To add a macro, type
{at the appropriate position in the API URL (within the Set API URL field), and select the desired macro from the dropdown list.{now}– The current datetime{now-1}– The datetime one time unit before the current datetime{now+1}– The datetime one time unit after the current datetimecustom– Datetime macros can reference any number of time units before or after the current datetime — for example, enter(now-7)to indicate the datetime seven time units before the current datetime
-
Select the format that will be applied to datetime macros from the Date Format for Date/Time Macro pulldown menu. This format will be applied to the base datetime value of the macro — i.e., the value of
{now}in{now-1}. Adobe Experience Platform APIs typically accept ISO 8601 date-time strings (e.g.,2024-01-01T00:00:00Z) or Unix epoch milliseconds. -
Select the datetime unit that will be used to perform mathematical operations in the included macro(s) from the Time Unit for Operations pulldown menu — for example, for the macro
{now-1}, whenDayis selected,{now-1}will be converted to the datetime one day before the current datetime.
Lookup-Based Macros (API URL)
Column values from existing lookups can also be included as macros in the API URL. Lookup-based macros allow you to reference data from previously configured data sources or lookups, enabling dynamic API endpoints that can adapt based on existing data.
Lookup-based macros are useful when you need to reference Adobe Experience Platform resource IDs — such as dataset IDs, segment IDs, or schema IDs — that are stored in another Nexla data source.
-
To include a lookup column value macro, select the relevant lookup from the Add Lookups to Supported Macros pulldown menu.
-
Type
{at the appropriate position in the API URL, and select the lookup column-based macro from the dropdown list. Lookup-based macros are automatically populated into the macro list when a lookup is selected in the Add Lookups to Supported Macros pulldown menu.
Path to Data
If only a subset of the data returned by the API endpoint is needed, you can designate the part of the response that should be included in the Nexset(s) produced from this source by specifying the path to the relevant data within the response. Adobe Experience Platform API responses typically return data wrapped in objects with metadata, pagination cursors, and links.
For example, a request to the Catalog Service to list datasets returns a JSON object where each key is a dataset ID and the value is the dataset metadata. The Segmentation API returns segments in a segments array within the response body.
Path to Data is essential for Adobe Experience Platform API responses, which often include wrapper objects, pagination metadata, and response envelopes. Specifying the correct path ensures Nexla correctly parses each record from the response.
-
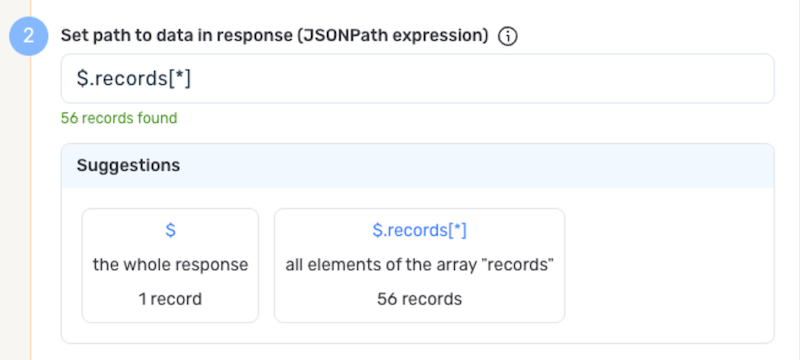
To specify which data should be treated as relevant in responses from this source, enter the path to the relevant data in the Set Path to Data in Response field.
- For responses in JSON format, enter the JSON path that points to the object or array that should be treated as relevant data. JSON paths use dot notation (e.g.,
$.data[*]to access an array of items within a data object, or$.segments[*]to access the segments array from the Segmentation API).
Path to Data Example:If the Segmentation API response includes a top-level
segmentsarray containing segment definitions, the path to the relevant data would be entered as$.segments[*]. - For responses in JSON format, enter the JSON path that points to the object or array that should be treated as relevant data. JSON paths use dot notation (e.g.,
Autogenerate Path Suggestions
Nexla can also autogenerate data path suggestions based on the response from the API endpoint. These suggested paths can be used as-is or modified to exactly suit your needs.
-
To use this feature, click the Test button next to the Set API URL field to fetch a sample response from the API endpoint. Suggested data paths generated based on the content and format of the response will be displayed in the Suggestions box below the Set Path to Data in Response field.
-
Click on a suggestion to automatically populate the Set Path to Data in Response field with the corresponding path. The populated path can be modified directly within the field if further customization is needed.
Metadata
If metadata is included in the response but is located outside of the defined path to relevant data, you can configure Nexla to include this data as common metadata in each record. Adobe Experience Platform API responses often include pagination details, request IDs, and total record counts alongside the actual data.
Metadata paths are particularly useful for preserving Adobe Experience Platform response context like total record counts, pagination cursors (e.g., _links.next), or request correlation IDs that apply to all records in the response.
-
To specify the location of metadata that should be included with each record, enter the path to the relevant metadata in the Path to Metadata in Response field.
- For responses in JSON format, enter the JSON path to the object or array that contains the metadata.
Request Headers
-
If Nexla should include any additional request headers in API calls to this source, enter the headers and corresponding values as comma-separated pairs in the Request Headers field (e.g.,
header1:value1,header2:value2).Adobe Experience Platform APIs require several standard headers on every request. Nexla automatically provides the
Authorization(Bearer token),x-api-key(Client ID),x-gw-ims-org-id(Organization ID), andx-sandbox-nameheaders from the credential configuration. Additional headers you may need to include manually are:x-request-id— A custom UUID value you can include to trace requests in Adobe logsAccept— Required by some APIs (e.g.,application/vnd.adobe.xed+jsonfor Schema Registry requests)Content-Type— Required for POST requests (e.g.,application/json)
You do not need to include
Authorization,x-api-key,x-gw-ims-org-id, orx-sandbox-namein the Request Headers field — these are handled automatically by Nexla using the values from your Adobe Experience Platform credential.
Endpoint Testing
After configuring all settings for the selected endpoint, Nexla can retrieve a sample of the data that will be fetched according to the current configuration. This allows you to verify that the source is configured correctly before saving.
-
To test the current endpoint configuration, click the Test button to the right of the endpoint selection menu. Sample data will be fetched and displayed in the Endpoint Test Result panel on the right.
-
If the sample data is not as expected, review the selected endpoint and associated settings, and make any necessary adjustments. Then, click the Test button again, and check the sample data to ensure that the correct information is displayed.
Save & Activate the Source
- Once all of the relevant steps in the above sections have been completed, click the Create button in the upper right corner of the screen to save and create the new Adobe Experience Platform data source. Nexla will now begin ingesting data from the configured endpoint and will organize any data that it finds into one or more Nexsets.