Veeva Vault is an enterprise cloud content management and compliance platform built for the life sciences industry. It manages the complete lifecycle of documents, binders, objects, and metadata across clinical, regulatory, quality, and commercial functions. Follow the instructions below to create a new data flow that ingests data from a Veeva Vault source in Nexla.
Create a New Data Flow
-
To create a new data flow, navigate to the Integrate section, and click the New Data Flow button. Then, select the desired flow type from the list, and click the Create button.
-
Select the Veeva Vault connector tile from the list of available connectors. Then, select the credential that will be used to connect to the Veeva Vault instance, and click Next; or, create a new Veeva Vault credential for use in this flow.
-
In Nexla, Veeva Vault data sources can be created using pre-built endpoint templates, which expedite source setup for common Veeva Vault API endpoints. Each template is designed specifically for the corresponding Veeva Vault endpoint, making source configuration easy and efficient.
• To configure this source using a template, follow the instructions in Configure Using a Template.
Veeva Vault sources can also be configured manually, allowing you to ingest data from Veeva Vault endpoints not included in the pre-built templates or apply further customizations to exactly suit your needs.
• To configure this source manually, follow the instructions in Configure Manually.
Nexla provides pre-built templates that can be used to rapidly configure data sources to ingest data from common Veeva Vault API endpoints. Each template is designed specifically for the corresponding Veeva Vault endpoint, making data source setup easy and efficient.
Endpoint Settings
- Select the endpoint from which this source will fetch data from the Endpoint pulldown menu. Available endpoint templates are listed in the expandable boxes below. Click on an endpoint to see more information about it and how to configure your data source for this endpoint.
Retrieve Delegations
Retrieves a list of Vault delegations available to the currently authenticated user. A vault delegation grants a user access to another Vault instance, allowing them to work across multiple vaults. Use this endpoint to enumerate which vaults are accessible via delegation for the current user.
- This endpoint requires no additional required parameters beyond selecting it. The API automatically returns all delegations available to the authenticated user.
- Optionally, enter an API version string in the API Version field to target a specific Vault API version (e.g.,
v25.3). The default value is v25.3. Update this value if your Vault instance requires a different API version.
Retrieve API Versions
Retrieves a list of all API versions currently available for the connected Vault instance. This endpoint is useful for discovering which API versions are supported by your Vault, which is helpful when planning upgrades or ensuring compatibility with a specific version.
- This endpoint requires no parameters. It calls the top-level
/api/ endpoint, which returns a list of all supported API versions without requiring authentication parameters. - No additional configuration is needed — select this endpoint and click Test to retrieve the version list.
Submitting a Query
Submits a Vault Query Language (VQL) statement to retrieve data from your Vault. VQL uses a SQL-like syntax and can query documents, binders, vault objects, and their associated fields. This is the most flexible endpoint for retrieving structured data from Veeva Vault, supporting filters, joins, ordering, and pagination automatically via next-page links.
VQL query strings sent via this endpoint can be up to 50,000 characters. For complex or large result sets, use WHERE clauses to limit the data returned. Full VQL syntax documentation is available at the Veeva Vault Query Language Reference.
List All Documents
Retrieves all documents from the connected Vault using offset-based pagination. This endpoint returns document metadata for every document in the Vault, including document IDs, names, types, statuses, and other standard document fields. Use this endpoint when you need a complete inventory of all documents in the Vault.
- No required parameters are needed for this endpoint. Nexla automatically handles offset-based pagination, retrieving up to 1,000 records per page and continuing until all documents are retrieved.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
For very large Vaults, the "Submitting a Query" endpoint using VQL is often more efficient, as it allows you to filter documents by type, status, or other criteria rather than retrieving all documents at once.
Get Document
Retrieves the metadata for a single document by its unique document ID. Use this endpoint when you know the specific document ID and need to retrieve its full metadata record, including all document fields and properties.
- Enter the numeric document ID in the Document ID field. This field is required. Document IDs can be obtained from the List All Documents endpoint or from VQL queries against the
documents object. - Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
The response data path for this endpoint is $.data, meaning Nexla will extract the document metadata object directly from the API response.
List Document Versions
Retrieves all versions of a specific document. Veeva Vault maintains a complete version history for each document, with major and minor version numbers. Use this endpoint to enumerate all versions of a document, including their version numbers, statuses, and modification dates.
- Enter the document ID in the Document ID field. This field is required. The endpoint will return all versions associated with the specified document.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Get Document Version
Retrieves the metadata for a specific version of a document, identified by document ID, major version number, and minor version number. In Veeva Vault, each document version is uniquely identified by the combination of these three values. Use this endpoint when you need detailed metadata for a particular version of a document.
- Enter the document ID in the Document ID field. This field is required.
- Enter the major version number in the Major Version field. This field is required. In Vault, the major version increments when a document is promoted through a lifecycle state (e.g., from Draft to Approved). For example, enter
1 for version 1.x. - Enter the minor version number in the Minor Version field. This field is required. The minor version increments during the drafting process. For example, enter
0 for version 1.0. - Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Download Document File
Downloads the source file (e.g., PDF, Word, Excel) attached to the latest version of a specific document. Use this endpoint when you need to retrieve the actual document file content, rather than just its metadata.
- Enter the document ID in the Document ID field. This field is required. Nexla will retrieve the file attachment for the most recent version of the specified document.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
This endpoint downloads the raw file body. The file is streamed and processed by Nexla as a file-type response. Ensure your Nexla flow is configured to handle binary file data appropriately downstream.
Download Document Version File
Downloads the source file for a specific version of a document, identified by document ID, major version, and minor version number. Use this endpoint when you need to retrieve the file content of a historical version rather than the latest version.
- Enter the document ID in the Document ID field. This field is required.
- Enter the major version number in the Major Version field. This field is required.
- Enter the minor version number in the Minor Version field. This field is required.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Download Document Version Rendition File
Downloads a rendition file for a specific version of a document. A rendition is a converted or generated representation of a document — for example, a viewable PDF rendition generated from a Word source file, or an imported rendition uploaded separately. Use this endpoint to retrieve rendition files for use in downstream processing or distribution.
Download Document Attachment Version
Downloads a specific version of a file attachment associated with a document. Documents in Veeva Vault can have one or more attachments — supplementary files linked to the document record. Use this endpoint to retrieve a specific version of a document-level attachment.
- Enter the document ID in the Document ID field. This field is required.
- Enter the attachment ID in the Attachment ID field. This field is required. Attachment IDs can be retrieved via the Veeva Vault API's document attachments endpoint.
- Enter the attachment version number in the Attachment Version field. This field is required.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Download Document Version Attachment Version
Downloads an attachment file from a specific version of a document. This endpoint provides granular control, allowing you to retrieve a specific version of an attachment that belongs to a specific version of a document. Use this endpoint when working with historical document versions that each have their own attachment sets.
- Enter the document ID in the Document ID field. This field is required.
- Enter the major document version number in the Major Version field. This field is required.
- Enter the minor document version number in the Minor Version field. This field is required.
- Enter the attachment ID in the Attachment ID field. This field is required.
- Enter the attachment version number in the Attachment Version field. This field is required.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Read Annotations by Document Version and Type
Retrieves annotations for a specific version of a document. Annotations in Veeva Vault include comments, notes, and markup placed on document renditions by reviewers during the review and approval process. Use this endpoint to extract annotation data for auditing, reporting, or downstream processing.
- Enter the document ID in the Document ID field. This field is required.
- Enter the major version number in the Major Version field. This field is required.
- Enter the minor version number in the Minor Version field. This field is required.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Annotation data is returned in the $.annotations[*] path of the API response. Each annotation record includes fields for annotation type, content, placement, author, and timestamp.
Retrieve Document Template Metadata
Retrieves metadata for all document templates configured in the Vault. Document templates in Veeva Vault are pre-configured document structures that define required fields, lifecycle states, and classification for specific document types. Use this endpoint to audit available document templates or understand the metadata structure of templates in your Vault.
- No required parameters are needed for this endpoint. It returns all document template metadata available in the connected Vault.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve Document Template Collection
Retrieves a collection of all document templates available in the Vault, including their names and IDs. Use this endpoint to list available templates for discovery, reporting, or to obtain template IDs needed for document creation operations.
- No required parameters are needed for this endpoint. It returns the complete list of document templates in the Vault.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve All Binders
Retrieves a collection of all binders from the Vault using offset-based pagination. Binders in Veeva Vault are containers that organize related documents into a hierarchical structure — similar to a folder or dossier. They are commonly used in regulatory submissions (e.g., eCTD), quality management systems, and clinical trial master files. Use this endpoint to retrieve binder metadata for all binders in the Vault.
- No required parameters are needed for this endpoint. Nexla automatically handles offset-based pagination, retrieving up to 1,000 records per page until all binders are returned.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve Binder
Retrieves a single binder by its unique ID, including the binder's metadata and node structure. Use this endpoint when you need the full details of a specific binder, including its sections, subsections, and the documents linked within it.
- Enter the binder ID in the Binder ID field. This field is required. Binder IDs can be obtained from the Retrieve All Binders endpoint or from VQL queries against the binders object.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve Binder Template Metadata
Retrieves metadata for binder templates in the Vault. Binder templates define the structure and configuration for creating new binders of a specific type. Use this endpoint to discover available binder templates and understand their configuration.
- No required parameters are needed for this endpoint.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve Binder Template Node Metadata
Retrieves metadata for binder template nodes. Binder template nodes define the section structure within a binder template — for example, the sections and subsections required in a regulatory submission binder. Use this endpoint to understand the node hierarchy available within binder templates.
- No required parameters are needed for this endpoint. It returns the complete set of binder template node metadata for the Vault.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve Object Record Attachments
Retrieves the list of file attachments associated with a specific record in a Vault object. Vault objects are structured data entities (similar to database tables) used to manage business data such as products, studies, sites, or custom records. Attachments on object records are files linked to those records. Use this endpoint to retrieve attachment metadata for a given object record.
- Enter the API name of the Vault object in the Object Name field. This field is required. Vault object API names use the
__v suffix convention for standard objects — for example, product__v, study__v, or site__v. Custom objects use the __c suffix. - Enter the unique record ID in the Object Record ID field. This field is required. Record IDs can be obtained using VQL queries against the target object.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Download Object Record Attachment File
Downloads a specific version of a file attachment associated with an object record. Use this endpoint to retrieve the actual file content of an attachment on a Vault object record.
- Enter the API name of the Vault object in the Object Name field. This field is required (e.g.,
product__v). - Enter the object record ID in the Object Record ID field. This field is required.
- Enter the attachment ID in the Attachment ID field. This field is required.
- Enter the attachment version number in the Attachment Version field. This field is required.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve Object Metadata
Retrieves the metadata schema for a specific Vault object, including its fields, field types, and configuration. Use this endpoint to discover the available fields and their data types for a given Vault object before constructing VQL queries or building destination payloads.
- Enter the API name of the Vault object in the Object Name field. This field is required. Use the Retrieve Object Collection endpoint or Vault's Admin interface to find valid object API names.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve Object Field Metadata
Retrieves detailed metadata for a specific field within a Vault object. This includes field type, label, required status, picklist values, and other field-level configuration. Use this endpoint to understand the constraints and options for a specific field before writing data to it.
- Enter the API name of the Vault object in the Object Name field. This field is required.
- Enter the API name of the field in the Field Name field. This field is required. Field API names follow the same naming convention as object names — standard fields use
__v and custom fields use __c. - Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve Object Collection
Retrieves a list of all available Vault objects and their metadata. This endpoint returns an overview of every object configured in the Vault, including both standard Veeva objects and custom objects specific to your organization. Use this endpoint to discover all available objects before querying or writing data.
- No required parameters are needed for this endpoint. It returns all object metadata for the connected Vault instance.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve Object Record
Retrieves a single record from a Vault object by its unique record ID. Use this endpoint when you need the complete field data for a specific record in a Vault object, such as a product, study, or custom business object.
- Enter the API name of the Vault object in the Object Name field. This field is required (e.g.,
product__v or study__v). - Enter the unique record ID in the Record ID field. This field is required. Record IDs can be retrieved using VQL queries against the target object.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Retrieve All Users
Retrieves all users in the Vault instance, including their user IDs, names, email addresses, roles, and status. Use this endpoint to audit Vault user accounts, synchronize user data with external systems, or build user-based reporting.
- No required parameters are needed for this endpoint. Nexla automatically handles offset-based pagination, retrieving up to 1,000 users per page.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
Validate Session User
Retrieves information about the currently authenticated user — the Vault user whose credentials are being used in the Nexla credential. This endpoint is useful for verifying that authentication is working correctly and confirming which user account and permissions are active for the current session.
- No required parameters are needed for this endpoint. It returns the profile and access details for the authenticated session user.
- Optionally, update the API Version field if your Vault requires a version other than the default
v25.3.
This endpoint calls /api/{version}/objects/users/me. It is also used internally by Nexla to validate the credential at the time of creation.
Endpoint Testing
Once the selected endpoint template has been configured, Nexla can retrieve a sample of the data that will be fetched according to the current settings. This allows users to verify that the source is configured correctly before saving.
-
To test the current endpoint configuration, click the Test button to the right of the endpoint selection menu. Sample data will be fetched & displayed in the Endpoint Test Result panel on the right.
-
If the sample data is not as expected, review the selected endpoint and associated settings, and make any necessary adjustments. Then, click the Test button again, and check the sample data to ensure that the correct information is displayed.
Veeva Vault data sources can be manually configured to ingest data from any valid Veeva Vault API endpoint. Manual configuration provides maximum flexibility for accessing endpoints not covered by pre-built templates or when you need custom API configurations.
With manual configuration, you can also create more complex Veeva Vault sources, such as sources that use chained API calls or sources with custom request headers for specific API behaviors.
API Method
-
To manually configure this source, select the Advanced tab at the top of the configuration screen.
-
Select the API method that will be used for calls to the Veeva Vault API from the Method pulldown menu. The most common methods for Veeva Vault source operations are:
- GET: For retrieving documents, binders, objects, users, and metadata
- POST: For submitting VQL queries (the Vault query endpoint accepts POST with the query in the request body)
API Endpoint URL
- Enter the URL of the Veeva Vault API endpoint from which this source will fetch data in the Set API URL field. Veeva Vault API URLs follow the pattern
https://{'{vault_dns}'}/api/{'{version}'}/{endpoint_path}.
Use the Vault DNS from your credential as the host component of the URL. For example, a URL to retrieve all documents would be https://mycompany.veevavault.com/api/v25.3/objects/documents. Refer to the Veeva Vault API Reference for the full list of available endpoints and their URL patterns.
Date/Time Macros (API URL)
Optional
Optionally, the API URL can be customized using macros—all macros added to the API URL will be converted into values when Nexla executes the API call. Macros are dynamic placeholders that allow you to create flexible API endpoints that can adapt to different time periods or data requirements.
Date/time macros are useful for Vault API calls that include date-based query parameters, such as filtering documents modified after a specific date.
-
To add a macro, type { at the appropriate position in the API URL (within the Set API URL field), and select the desired macro from the dropdown list.
{now} – The current datetime{now-1} – The datetime one time unit before the current datetime{now+1} – The datetime one time unit after the current datetimecustom – Datetime macros can reference any number of time units before or after the current datetime—for example, enter (now-4) to indicate the datetime four time units before the current datetime
-
Select the format that will be applied to datetime macros from the Date Format for Date/Time Macro pulldown menu. This format will be applied to the base datetime value of the macro—i.e., the value of {now} in {now-1}. Veeva Vault typically expects dates in yyyy-MM-dd format.
-
Select the datetime unit that will be used to perform mathematical operations in the included macro(s) from the Time Unit for Operations pulldown menu—for example, for the macro {now-1}, when Day is selected, {now-1} will be converted to the datetime one day before the current datetime.
Lookup-Based Macros (API URL)
Optional
Column values from existing lookups can also be included as macros in the API URL. Lookup-based macros allow you to reference data from previously configured data sources or lookups, enabling dynamic API endpoints that can adapt based on existing data.
Lookup-based macros are particularly useful when building chained Vault API calls — for example, first retrieving a list of document IDs and then using those IDs as parameters in subsequent API calls.
-
To include a lookup column value macro, select the relevant lookup from the Add Lookups to Supported Macros pulldown menu.
-
Type { at the appropriate position in the API URL, and select the lookup column-based macro from the dropdown list. Lookup-based macros are automatically populated into the macro list when a lookup is selected in the Add Lookups to Supported Macros pulldown menu.
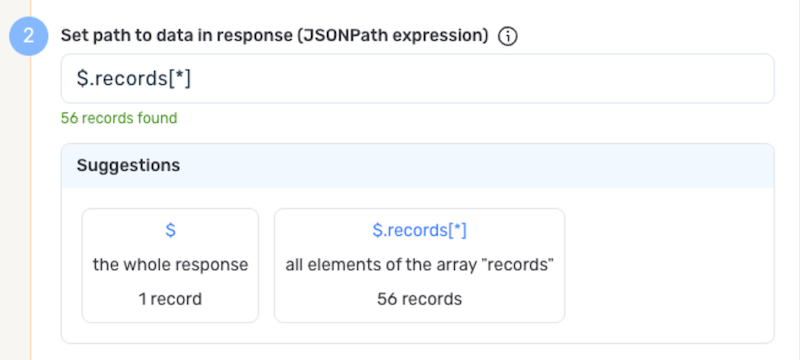
If only a subset of the data returned by the Vault API endpoint is needed, designate the relevant portion of the response by specifying the path to data within the response. Vault API responses typically include a responseStatus field, pagination metadata, and the actual data array — specifying the path helps Nexla extract just the relevant records.
For example, when calling the List All Documents endpoint, the API returns a data array containing document records along with a responseMessage and responseStatus. By entering the path $.data[*], you can configure Nexla to treat each element of the returned array as a separate record.
For most Veeva Vault API endpoints, the relevant data is found at paths such as $.data[*], $.users[*], $.objects[*], $.delegations[*], or $.versions[*]. Refer to the Veeva Vault API Reference for the specific response structure of each endpoint.
Autogenerate Path Suggestions
Nexla can also autogenerate data path suggestions based on the response from the API endpoint. These suggested paths can be used as-is or modified to exactly suit your needs.
-
To use this feature, click the Test button next to the Set API URL field to fetch a sample response from the API endpoint. Suggested data paths generated based on the content & format of the response will be displayed in the Suggestions box below the Set Path to Data in Response field.
-
Click on a suggestion to automatically populate the Set Path to Data in Response field with the corresponding path. The populated path can be modified directly within the field if further customization is needed.
If metadata is included in the response but is located outside of the defined path to relevant data, you can configure Nexla to include this data as common metadata in each record. Vault API responses frequently include responseDetails objects containing pagination information, total counts, and next-page URLs that may be useful to preserve as metadata.
Metadata paths are useful for preserving Vault API response context such as responseDetails.total (total record count) or responseDetails.pageoffset (current page offset) alongside each retrieved record.
-
If Nexla should include any additional request headers in API calls to this source, enter the headers & corresponding values as comma-separated pairs in the Request Headers field (e.g., header1:value1,header2:value2). For example, the Vault Query Language endpoint uses X-VaultAPI-DescribeQuery:true to include field metadata in the response.
You do not need to include the Authorization header — it is automatically handled by the Veeva Vault credential configuration. Only include headers that are specific to the individual endpoint being configured.
Endpoint Testing
After configuring all settings for the selected endpoint, Nexla can retrieve a sample of the data that will be fetched according to the current configuration. This allows users to verify that the source is configured correctly before saving.
-
To test the current endpoint configuration, click the Test button to the right of the endpoint selection menu. Sample data will be fetched & displayed in the Endpoint Test Result panel on the right.
-
If the sample data is not as expected, review the selected endpoint and associated settings, and make any necessary adjustments. Then, click the Test button again, and check the sample data to ensure that the correct information is displayed.
Save & Activate the Source
- Once all of the relevant steps in the above sections have been completed, click the Create button in the upper right corner of the screen to save and create the new Veeva Vault data source. Nexla will now begin ingesting data from the configured endpoint and will organize any data that it finds into one or more Nexsets.