Data Source
Bamboo HR
Create a New Data Flow
-
To create a new data flow, navigate to the Integrate section, and click the New Data Flow button. Then, select the desired flow type from the list, and click the Create button.
-
Select the BambooHR connector tile from the list of available connectors. Then, select the credential that will be used to connect to the BambooHR instance, and click Next; or, create a new BambooHR credential for use in this flow.
-
In Nexla, BambooHR data sources can be created using pre-built endpoint templates, which expedite source setup for common BambooHR endpoints. Each template is designed specifically for the corresponding BambooHR endpoint, making source configuration easy and efficient.
• To configure this source using a template, follow the instructions in Configure Using a Template.BambooHR sources can also be configured manually, allowing you to ingest data from BambooHR endpoints not included in the pre-built templates or apply further customizations to exactly suit your needs.
• To configure this source manually, follow the instructions in Configure Manually.
Configure Using a Template
Nexla provides pre-built templates that can be used to rapidly configure data sources to ingest data from common BambooHR endpoints. Each template is designed specifically for the corresponding BambooHR endpoint, making data source setup easy and efficient.
Endpoint Settings
-
Select the endpoint from which this source will fetch data from the Endpoint pulldown menu. Available endpoint templates are listed in the expandable boxes below. Click on an endpoint to see more information about it and how to configure your data source for this endpoint.
Endpoint Testing
Once the selected endpoint template has been configured, Nexla can retrieve a sample of the data that will be fetched according to the current settings. This allows users to verify that the source is configured correctly before saving.
-
To test the current endpoint configuration, click the Test button to the right of the endpoint selection menu. Sample data will be fetched & displayed in the Endpoint Test Result panel on the right.
-
If the sample data is not as expected, review the selected endpoint and associated settings, and make any necessary adjustments. Then, click the Test button again, and check the sample data to ensure that the correct information is displayed.
Configure Manually
BambooHR data sources can be manually configured to ingest data from any valid BambooHR API endpoint. Manual configuration provides maximum flexibility for accessing endpoints not covered by pre-built templates or when you need custom API configurations.
With manual configuration, you can also create more complex BambooHR sources, such as sources that use chained API calls to fetch data from multiple endpoints or sources that require custom authentication headers or request parameters.
API Method
-
To manually configure this source, select the Advanced tab at the top of the configuration screen.
-
Select the API method that will be used for calls to the BambooHR API from the Method pulldown menu. The BambooHR API primarily uses GET requests for data retrieval operations. The most common methods are:
- GET: For retrieving data from the API (most common for BambooHR)
- POST: For creating resources or triggering actions
- PUT: For updating existing data
- PATCH: For partial updates to existing data
- DELETE: For removing data
API Endpoint URL
- Enter the URL of the BambooHR API endpoint from which this source will fetch data in the Set API URL field. This should be the complete URL including the protocol (https://) and any required path parameters. BambooHR API endpoints typically follow the pattern
https://api.bamboohr.com/api/gateway.php/{companyDomain}/v1/{api_path}where{companyDomain}is your company subdomain and{api_path}is the specific API path.
Ensure the API endpoint URL is correct and accessible with your current credentials. The BambooHR API endpoint URL is automatically constructed based on your credential's company subdomain configuration. You can test the endpoint using the Test button after configuring the URL. BambooHR API requests require Basic Authentication with your API key, which is handled automatically by your credential configuration. For detailed information about BambooHR API endpoints and available APIs, see the BambooHR API documentation.
Path to Data
If only a subset of the data that will be returned by API endpoint is needed, you can designate the part(s) of the response that should be included in the Nexset(s) produced from this source by specifying the path to the relevant data within the response. This is particularly useful when API responses contain metadata, pagination information, or other data that you don't need for your analysis.
For example, when a request call is used to fetch a list of items, the API will typically return an array of records, along with metadata, in the response. By entering the path to the relevant data, you can configure Nexla to treat each element of the returned array as a record.
Path to Data is essential when API responses have nested structures. Without specifying the correct path, Nexla might not be able to properly parse and organize your data into usable records.
-
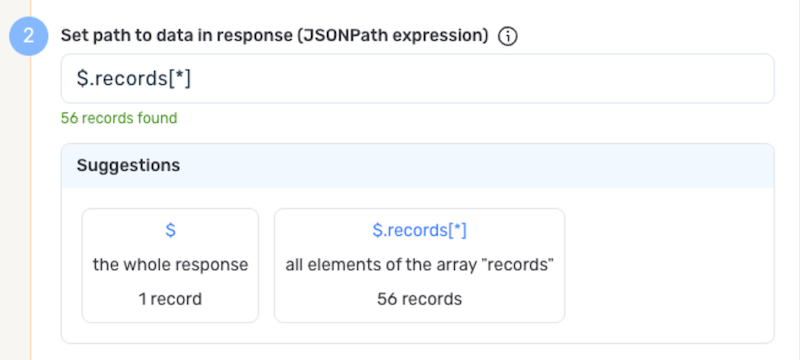
To specify which data should be treated as relevant in responses from this source, enter the path to the relevant data in the Set Path to Data in Response field.
-
For responses in JSON format enter the JSON path that points to the object or array that should be treated as relevant data. JSON paths use dot notation (e.g.,
$.employees[*]to access an array of employees within a response object). -
For responses in XML format, enter the XPath that points to the object/array containing relevant data. XPath uses slash notation (e.g.,
/response/data/itemto access item elements within a data element).
Path to Data Example:If the API response is in JSON format and includes a top-level object with an array named
employeesthat contains the relevant data, the path to the response would be entered as$.employees[*]. -
Autogenerate Path Suggestions
Nexla can also autogenerate data path suggestions based on the response from the API endpoint. These suggested paths can be used as-is or modified to exactly suit your needs.
-
To use this feature, click the Test button next to the Set API URL field to fetch a sample response from the API endpoint. Suggested data paths generated based on the content & format of the response will be displayed in the Suggestions box below the Set Path to Data in Response field.
-
Click on a suggestion to automatically populate the Set Path to Data in Response field with the corresponding path. The populated path can be modified directly within the field if further customization is needed.
Metadata
If metadata is included in the response but is located outside of the defined path to relevant data, you can configure Nexla to include this data as common metadata in each record. This is useful when you want to preserve important contextual information that applies to all records but isn't part of the main data array.
For example, when a request call is used to fetch a list of items, the API response will typically include an array of records along with metadata such as total count, pagination information, or request timestamps. In this case, if you have specified the path to the relevant data but metadata of interest is located in a different part of the response, you can specify a path to this metadata to include it with each record in the generated Nexset(s).
Metadata paths are particularly useful for preserving API response context like request IDs, timestamps, or summary statistics that apply to all records in the response.
-
To specify the location of metadata that should be included with each record, enter the path to the relevant metadata in the Path to Metadata in Response field.
- For responses in JSON format, enter the JSON path to the object or array that contains the metadata, and for responses in XML format, enter the XPath.
Request Headers
-
If Nexla should include any additional request headers in API calls to this source, enter the headers & corresponding values as comma-separated pairs in the Request Headers field (e.g.,
header1:value1,header2:value2). Additional headers are often required for API versioning, content type specifications, or custom authentication requirements.You do not need to include any headers already present in the credentials. Common headers like Authorization, Content-Type, and Accept are typically handled automatically by Nexla based on your credential configuration. BambooHR API requests require Basic Authentication with your API key, which is handled automatically by your credential configuration.
Endpoint Testing
After configuring all settings for the selected endpoint, Nexla can retrieve a sample of the data that will be fetched according to the current configuration. This allows users to verify that the source is configured correctly before saving.
-
To test the current endpoint configuration, click the Test button to the right of the endpoint selection menu. Sample data will be fetched & displayed in the Endpoint Test Result panel on the right.
-
If the sample data is not as expected, review the selected endpoint and associated settings, and make any necessary adjustments. Then, click the Test button again, and check the sample data to ensure that the correct information is displayed.
Save & Activate the Source
- Once all of the relevant steps in the above sections have been completed, click the Create button in the upper right corner of the screen to save and create the new BambooHR data source. Nexla will now begin ingesting data from the configured endpoint and will organize any data that it finds into one or more Nexsets.